 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual learning for surface defect segmentation by subnetwork creation and selection
Dec 08, 2023We introduce a new continual (or lifelong) learning algorithm called LDA-CP&S that performs segmentation tasks without undergoing catastrophic forgetting. The method is applied to two different surface defect segmentation problems that are learned incrementally, i.e. providing data about one type of defect at a time, while still being capable of predicting every defect that was seen previously. Our method creates a defect-related subnetwork for each defect type via iterative pruning and trains a classifier based on linear discriminant analysis (LDA). At the inference stage, we first predict the defect type with LDA and then predict the surface defects using the selected subnetwork. We compare our method with other continual learning methods showing a significant improvement -- mean Intersection over Union better by a factor of two when compared to existing methods on both datasets. Importantly, our approach shows comparable results with joint training when all the training data (all defects) are seen simultaneously
iPINNs: Incremental learning for Physics-informed neural networks
Apr 10, 2023



Physics-informed neural networks (PINNs) have recently become a powerful tool for solving partial differential equations (PDEs). However, finding a set of neural network parameters that lead to fulfilling a PDE can be challenging and non-unique due to the complexity of the loss landscape that needs to be traversed. Although a variety of multi-task learning and transfer learning approaches have been proposed to overcome these issues, there is no incremental training procedure for PINNs that can effectively mitigate such training challenges. We propose incremental PINNs (iPINNs) that can learn multiple tasks (equations) sequentially without additional parameters for new tasks and improve performance for every equation in the sequence. Our approach learns multiple PDEs starting from the simplest one by creating its own subnetwork for each PDE and allowing each subnetwork to overlap with previously learned subnetworks. We demonstrate that previous subnetworks are a good initialization for a new equation if PDEs share similarities. We also show that iPINNs achieve lower prediction error than regular PINNs for two different scenarios: (1) learning a family of equations (e.g., 1-D convection PDE); and (2) learning PDEs resulting from a combination of processes (e.g., 1-D reaction-diffusion PDE). The ability to learn all problems with a single network together with learning more complex PDEs with better generalization than regular PINNs will open new avenues in this field.
Cooperative data-driven modeling
Nov 23, 2022



Data-driven modeling in mechanics is evolving rapidly based on recent machine learning advances, especially on artificial neural networks. As the field matures, new data and models created by different groups become available, opening possibilities for cooperative modeling. However, artificial neural networks suffer from catastrophic forgetting, i.e. they forget how to perform an old task when trained on a new one. This hinders cooperation because adapting an existing model for a new task affects the performance on a previous task trained by someone else. The authors developed a continual learning method that addresses this issue, applying it here for the first time to solid mechanics. In particular, the method is applied to recurrent neural networks to predict history-dependent plasticity behavior, although it can be used on any other architecture (feedforward, convolutional, etc.) and to predict other phenomena. This work intends to spawn future developments on continual learning that will foster cooperative strategies among the mechanics community to solve increasingly challenging problems. We show that the chosen continual learning strategy can sequentially learn several constitutive laws without forgetting them, using less data to achieve the same error as standard training of one law per model.
Continual Prune-and-Select: Class-incremental learning with specialized subnetworks
Aug 09, 2022
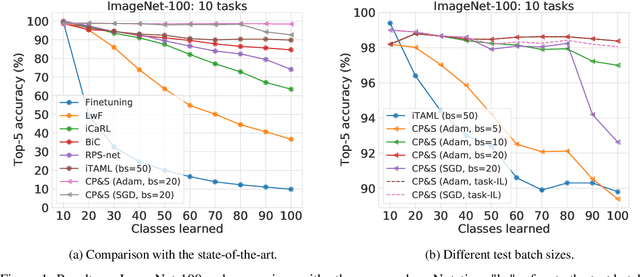

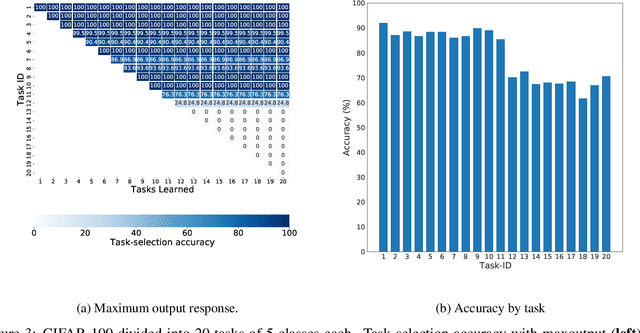
The human brain is capable of learning tasks sequentially mostly without forgetting. However, deep neural networks (DNNs) suffer from catastrophic forgetting when learning one task after another. We address this challenge considering a class-incremental learning scenario where the DNN sees test data without knowing the task from which this data originates. During training, Continual-Prune-and-Select (CP&S) finds a subnetwork within the DNN that is responsible for solving a given task. Then, during inference, CP&S selects the correct subnetwork to make predictions for that task. A new task is learned by training available neuronal connections of the DNN (previously untrained) to create a new subnetwork by pruning, which can include previously trained connections belonging to other subnetwork(s) because it does not update shared connections. This enables to eliminate catastrophic forgetting by creating specialized regions in the DNN that do not conflict with each other while still allowing knowledge transfer across them. The CP&S strategy is implemented with different subnetwork selection strategies, revealing superior performance to state-of-the-art continual learning methods tested on various datasets (CIFAR-100, CUB-200-2011, ImageNet-100 and ImageNet-1000). In particular, CP&S is capable of sequentially learning 10 tasks from ImageNet-1000 keeping an accuracy around 94% with negligible forgetting, a first-of-its-kind result in class-incremental learning. To the best of the authors' knowledge, this represents an improvement in accuracy above 20% when compared to the best alternative method.
Neural network relief: a pruning algorithm based on neural activity
Sep 22, 2021



Current deep neural networks (DNNs) are overparameterized and use most of their neuronal connections during inference for each task. The human brain, however, developed specialized regions for different tasks and performs inference with a small fraction of its neuronal connections. We propose an iterative pruning strategy introducing a simple importance-score metric that deactivates unimportant connections, tackling overparameterization in DNNs and modulating the firing patterns. The aim is to find the smallest number of connections that is still capable of solving a given task with comparable accuracy, i.e. a simpler subnetwork. We achieve comparable performance for LeNet architectures on MNIST, and significantly higher parameter compression than state-of-the-art algorithms for VGG and ResNet architectures on CIFAR-10/100 and Tiny-ImageNet. Our approach also performs well for the two different optimizers considered -- Adam and SGD. The algorithm is not designed to minimize FLOPs when considering current hardware and software implementations, although it performs reasonably when compared to the state of the art.