 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Cellular Automata Manifold
Jun 22, 2020
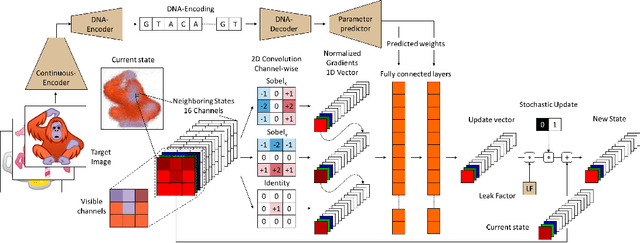
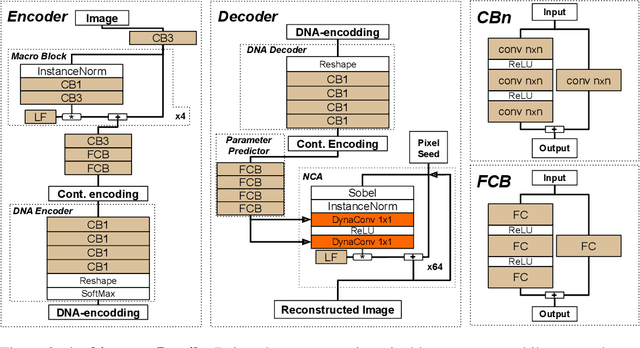

Very recently, a deep Neural Cellular Automata (NCA)[1] has been proposed to simulate the complex morphogenesis process with deep networks. This model learns to grow an image starting from a fixed single pixel. In this paper, we move a step further and propose a new model that extends the expressive power of NCA from a single image to an manifold of images. In biological terms, our approach would play the role of the transcription factors, modulating the mapping of genes into specific proteins that drive cellular differentiation, which occurs right before the morphogenesis. We accomplish this by introducing dynamic convolutions inside an Auto-Encoder architecture, for the first time used to join two different sources of information, the encoding and cell's environment information. The proposed model also extends the capabilities of the NCA to a general purpose network, which can be used in a broad range of problems. We thoroughly evaluate our approach in a dataset of synthetic emojis and also in real images of CIFAR-10.
Human Motion Prediction via Spatio-Temporal Inpainting
Dec 13, 2018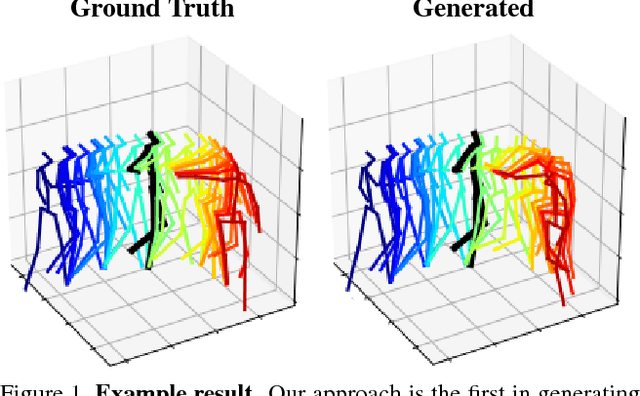
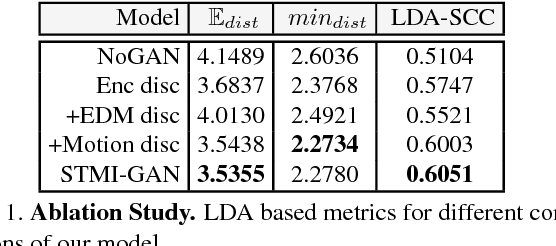
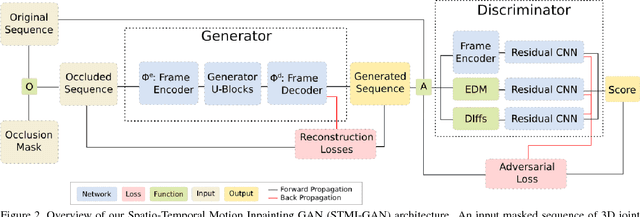

We propose a Generative Adversarial Network (GAN) to forecast 3D human motion given a sequence of observed 3D skeleton poses. While recent GANs have shown promising results, they can only forecast plausible human-like motion over relatively short periods of time, i.e. a few hundred milliseconds, and typically ignore the absolute position of the skeleton w.r.t. the camera. The GAN scheme we propose can reliably provide long term predictions of two seconds or more for both the non-rigid body pose and its absolute position, and can be trained in an self-supervised manner. Our approach builds upon three main contributions. First, we consider a data representation based on a spatio-temporal tensor of 3D skeleton coordinates which allows us to formulate the prediction problem as an inpainting one, for which GANs work particularly well. Secondly, we design a GAN architecture to learn the joint distribution of body poses and global motion, allowing us to hypothesize large chunks of the input 3D tensor with missing data. And finally, we argue that the L2 metric, which is considered so far by most approaches, fails to capture the actual distribution of long-term human motion. We therefore propose an alternative metric that is more correlated with human perception. Our experiments demonstrate that our approach achieves significant improvements over the state of the art for human motion forecasting and that it also handles situations in which past observations are corrupted by severe occlusions, noise and consecutive missing frames.