 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple steps are all you need: Frank-Wolfe and generalized self-concordant functions
Jun 03, 2021


Generalized self-concordance is a key property present in the objective function of many important learning problems. We establish the convergence rate of a simple Frank-Wolfe variant that uses the open-loop step size strategy $\gamma_t = 2/(t+2)$, obtaining a $\mathcal{O}(1/t)$ convergence rate for this class of functions in terms of primal gap and Frank-Wolfe gap, where $t$ is the iteration count. This avoids the use of second-order information or the need to estimate local smoothness parameters of previous work. We also show improved convergence rates for various common cases, e.g., when the feasible region under consideration is uniformly convex or polyhedral.
Parameter-free Locally Accelerated Conditional Gradients
Feb 12, 2021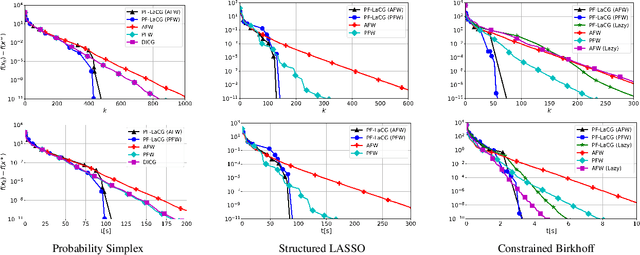
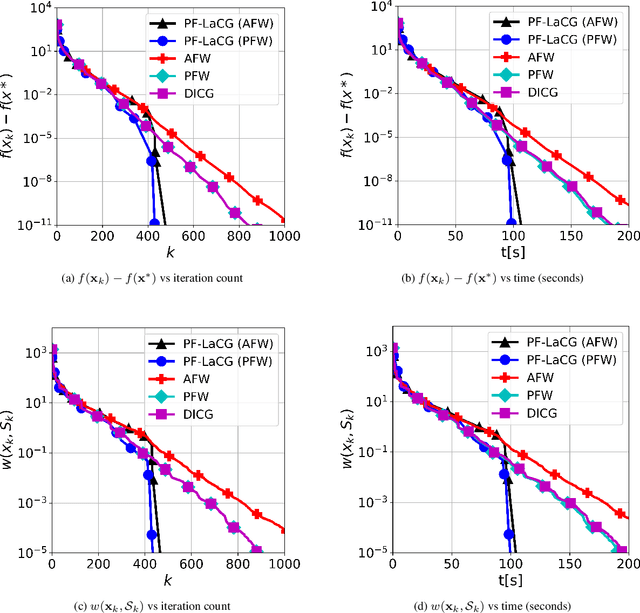
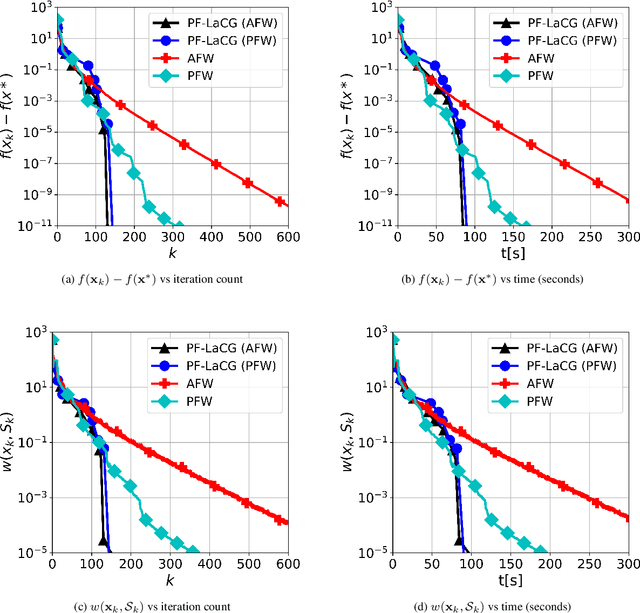
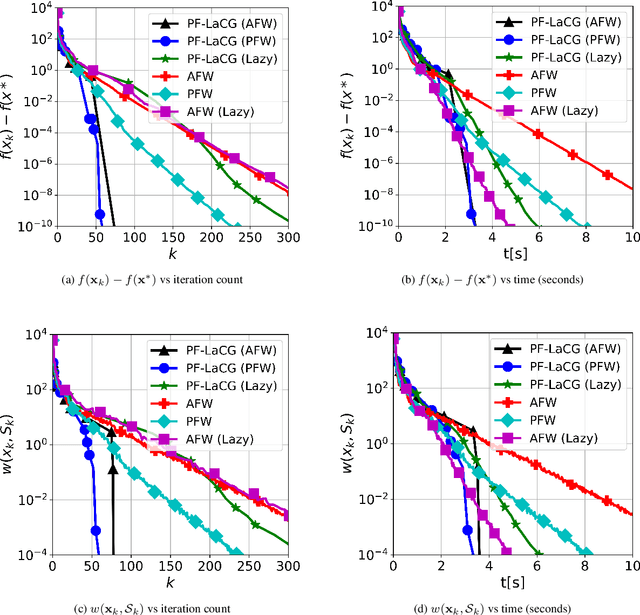
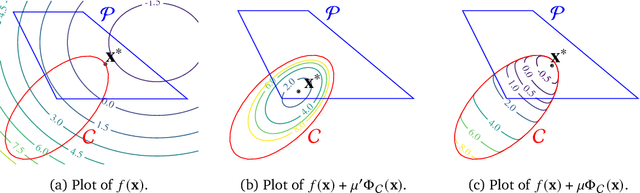
Projection-free conditional gradient (CG) methods are the algorithms of choice for constrained optimization setups in which projections are often computationally prohibitive but linear optimization over the constraint set remains computationally feasible. Unlike in projection-based methods, globally accelerated convergence rates are in general unattainable for CG. However, a very recent work on Locally accelerated CG (LaCG) has demonstrated that local acceleration for CG is possible for many settings of interest. The main downside of LaCG is that it requires knowledge of the smoothness and strong convexity parameters of the objective function. We remove this limitation by introducing a novel, Parameter-Free Locally accelerated CG (PF-LaCG) algorithm, for which we provide rigorous convergence guarantees. Our theoretical results are complemented by numerical experiments, which demonstrate local acceleration and showcase the practical improvements of PF-LaCG over non-accelerated algorithms, both in terms of iteration count and wall-clock time.
Second-order Conditional Gradients
Feb 20, 2020Constrained second-order convex optimization algorithms are the method of choice when a high accuracy solution to a problem is needed, due to the quadratic convergence rates these methods enjoy when close to the optimum. These algorithms require the solution of a constrained quadratic subproblem at every iteration. In the case where the feasible region can only be accessed efficiently through a linear optimization oracle, and computing first-order information about the function, although possible, is costly, the coupling of constrained second-order and conditional gradient algorithms leads to competitive algorithms with solid theoretical guarantees and good numerical performance.
Locally Accelerated Conditional Gradients
Jun 19, 2019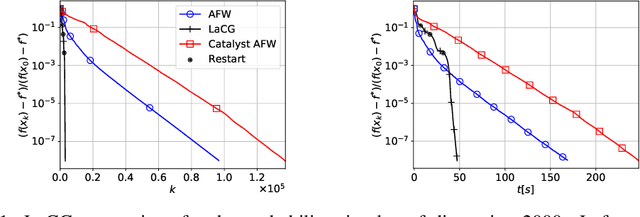
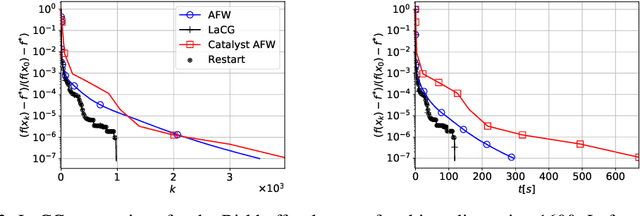
Conditional gradient methods form a class of projection-free first-order algorithms for solving smooth convex optimization problems. Apart from eschewing projections, these methods are attractive because of their simplicity, numerical performance, and the sparsity of the solutions outputted. However, they do not achieve optimal convergence rates. We present the Locally Accelerated Conditional Gradients algorithm that relaxes the projection-freeness requirement to only require projection onto (typically low-dimensional) simplices and mixes accelerated steps with conditional gradient steps to achieve local acceleration. We derive asymptotically optimal convergence rates for this algorithm. Our experimental results demonstrate the practicality of our approach; in particular, the speedup is achieved both in wall-clock time and per-iteration progress compared to standard conditional gradient methods and a Catalyst-accelerated Away-Step Frank-Wolfe algorithm.