 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Tensor Network Models for Low-Latency Jet Tagging on FPGAs
Jan 15, 2026We present a systematic study of Tensor Network (TN) models $\unicode{x2013}$ Matrix Product States (MPS) and Tree Tensor Networks (TTN) $\unicode{x2013}$ for real-time jet tagging in high-energy physics, with a focus on low-latency deployment on Field Programmable Gate Arrays (FPGAs). Motivated by the strict requirements of the HL-LHC Level-1 trigger system, we explore TNs as compact and interpretable alternatives to deep neural networks. Using low-level jet constituent features, our models achieve competitive performance compared to state-of-the-art deep learning classifiers. We investigate post-training quantization to enable hardware-efficient implementations without degrading classification performance or latency. The best-performing models are synthesized to estimate FPGA resource usage, latency, and memory occupancy, demonstrating sub-microsecond latency and supporting the feasibility of online deployment in real-time trigger systems. Overall, this study highlights the potential of TN-based models for fast and resource-efficient inference in low-latency environments.
Ultra-low latency quantum-inspired machine learning predictors implemented on FPGA
Sep 25, 2024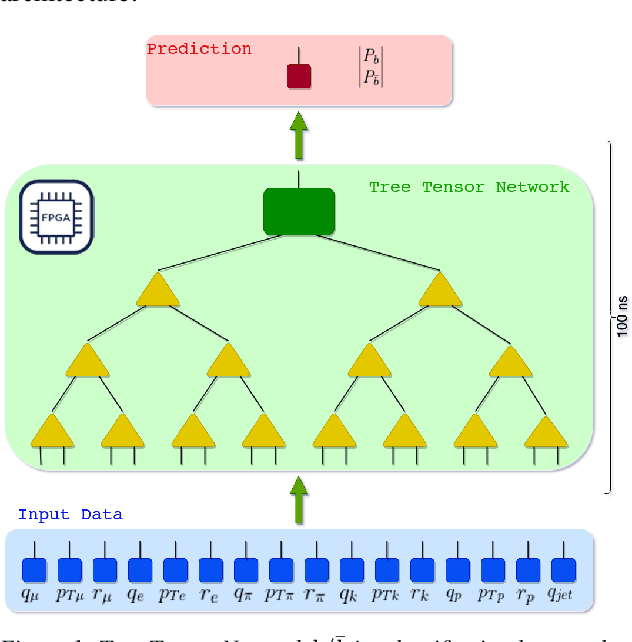
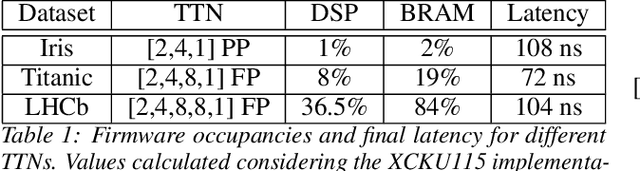
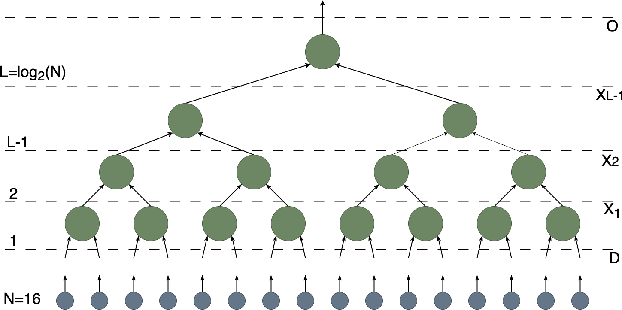

Tensor Networks (TNs) are a computational paradigm used for representing quantum many-body systems. Recent works have shown how TNs can also be applied to perform Machine Learning (ML) tasks, yielding comparable results to standard supervised learning techniques. In this work, we study the use of Tree Tensor Networks (TTNs) in high-frequency real-time applications by exploiting the low-latency hardware of the Field-Programmable Gate Array (FPGA) technology. We present different implementations of TTN classifiers, capable of performing inference on classical ML datasets as well as on complex physics data. A preparatory analysis of bond dimensions and weight quantization is realized in the training phase, together with entanglement entropy and correlation measurements, that help setting the choice of the TTN architecture. The generated TTNs are then deployed on a hardware accelerator; using an FPGA integrated into a server, the inference of the TTN is completely offloaded. Eventually, a classifier for High Energy Physics (HEP) applications is implemented and executed fully pipelined with sub-microsecond latency.