 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning for Sonar Image Classification
Apr 20, 2022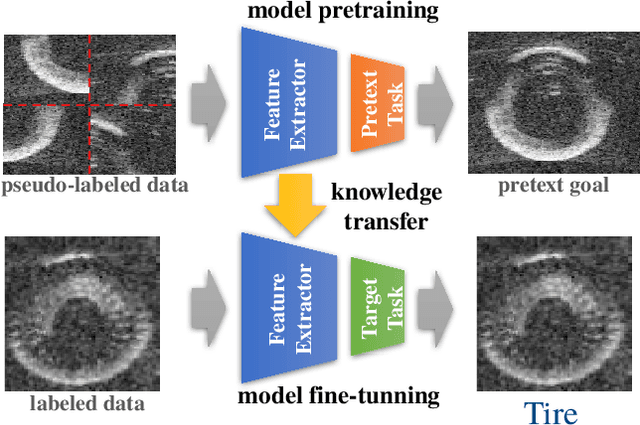

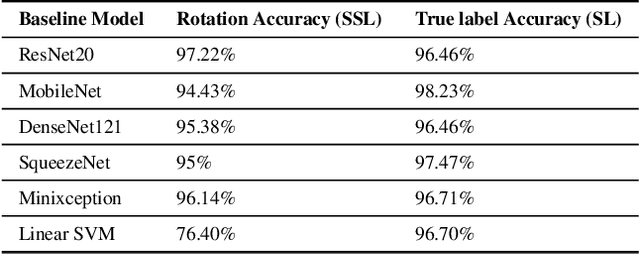
Self-supervised learning has proved to be a powerful approach to learn image representations without the need of large labeled datasets. For underwater robotics, it is of great interest to design computer vision algorithms to improve perception capabilities such as sonar image classification. Due to the confidential nature of sonar imaging and the difficulty to interpret sonar images, it is challenging to create public large labeled sonar datasets to train supervised learning algorithms. In this work, we investigate the potential of three self-supervised learning methods (RotNet, Denoising Autoencoders, and Jigsaw) to learn high-quality sonar image representation without the need of human labels. We present pre-training and transfer learning results on real-life sonar image datasets. Our results indicate that self-supervised pre-training yields classification performance comparable to supervised pre-training in a few-shot transfer learning setup across all three methods. Code and self-supervised pre-trained models are be available at https://github.com/agrija9/ssl-sonar-images
Anomaly Detection of Wind Turbine Time Series using Variational Recurrent Autoencoders
Dec 05, 2021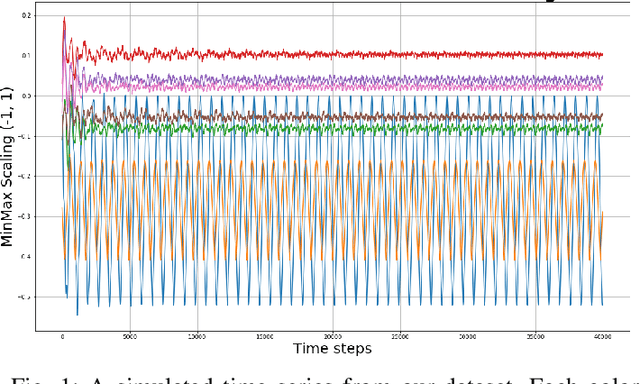
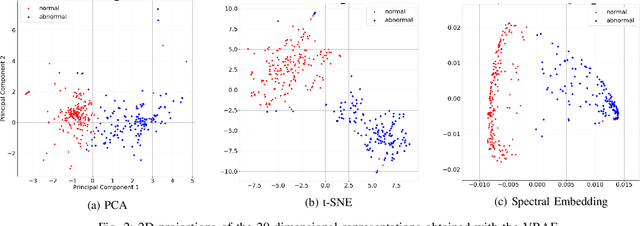
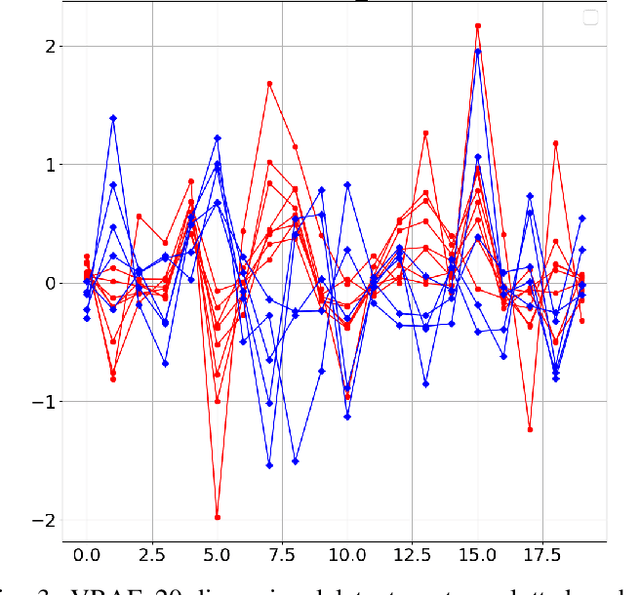
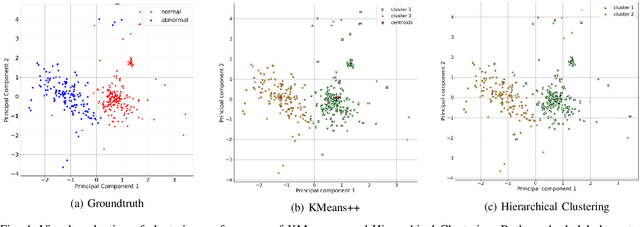
Ice accumulation in the blades of wind turbines can cause them to describe anomalous rotations or no rotations at all, thus affecting the generation of electricity and power output. In this work, we investigate the problem of ice accumulation in wind turbines by framing it as anomaly detection of multi-variate time series. Our approach focuses on two main parts: first, learning low-dimensional representations of time series using a Variational Recurrent Autoencoder (VRAE), and second, using unsupervised clustering algorithms to classify the learned representations as normal (no ice accumulated) or abnormal (ice accumulated). We have evaluated our approach on a custom wind turbine time series dataset, for the two-classes problem (one normal versus one abnormal class), we obtained a classification accuracy of up to 96$\%$ on test data. For the multiple-class problem (one normal versus multiple abnormal classes), we present a qualitative analysis of the low-dimensional learned latent space, providing insights into the capacities of our approach to tackle such problem. The code to reproduce this work can be found here https://github.com/agrija9/Wind-Turbines-VRAE-Paper.
Evaluation of Deep Neural Network Domain Adaptation Techniques for Image Recognition
Sep 28, 2021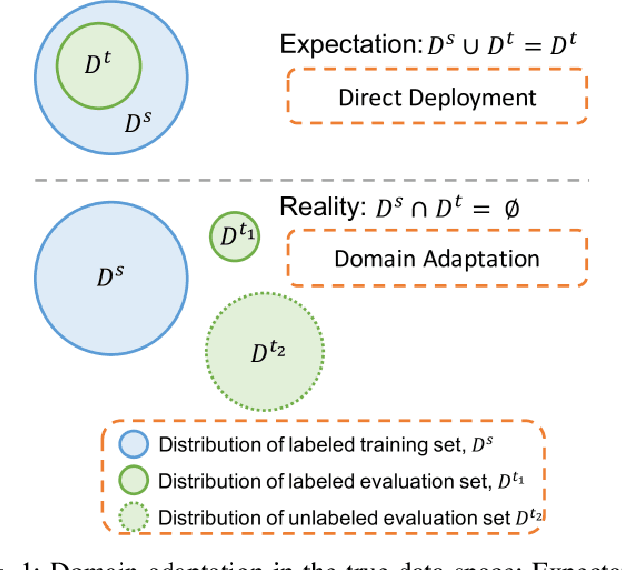
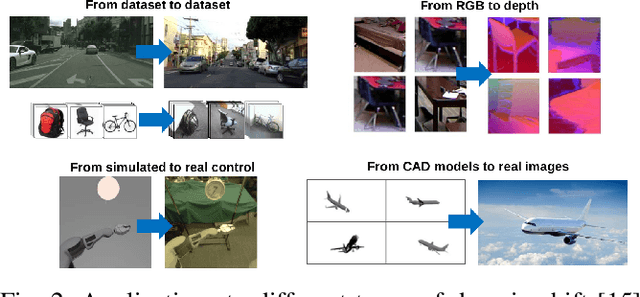
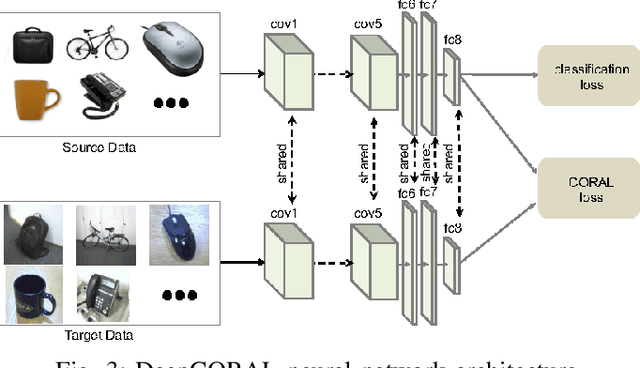
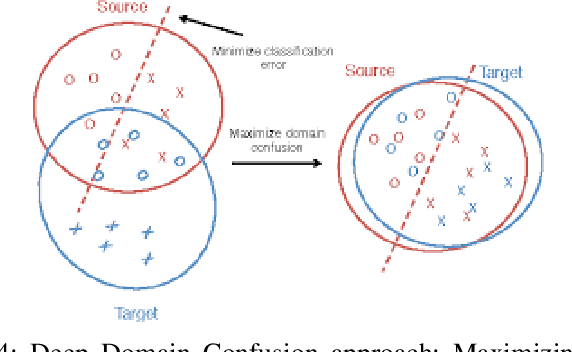
It has been well proved that deep networks are efficient at extracting features from a given (source) labeled dataset. However, it is not always the case that they can generalize well to other (target) datasets which very often have a different underlying distribution. In this report, we evaluate four different domain adaptation techniques for image classification tasks: DeepCORAL, DeepDomainConfusion, CDAN and CDAN+E. These techniques are unsupervised given that the target dataset dopes not carry any labels during training phase. We evaluate model performance on the office-31 dataset. A link to the github repository of this report can be found here: https://github.com/agrija9/Deep-Unsupervised-Domain-Adaptation.
Pre-trained Models for Sonar Images
Aug 02, 2021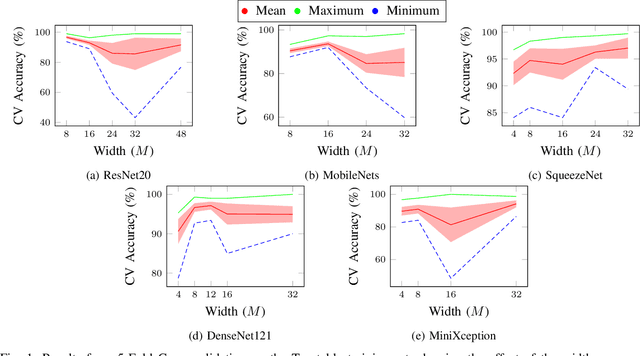
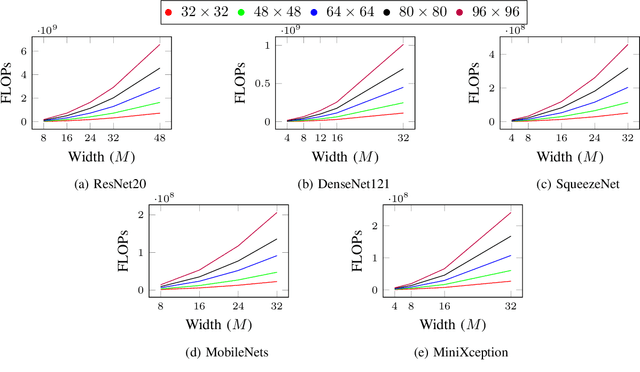

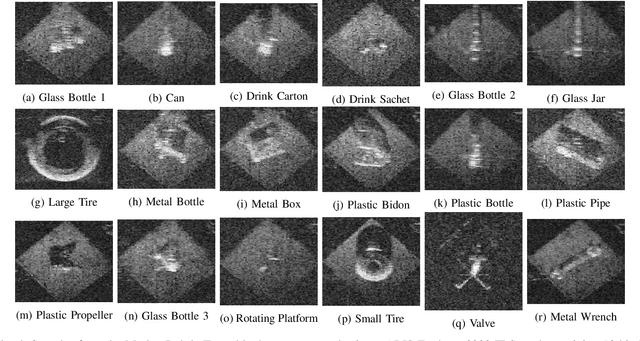
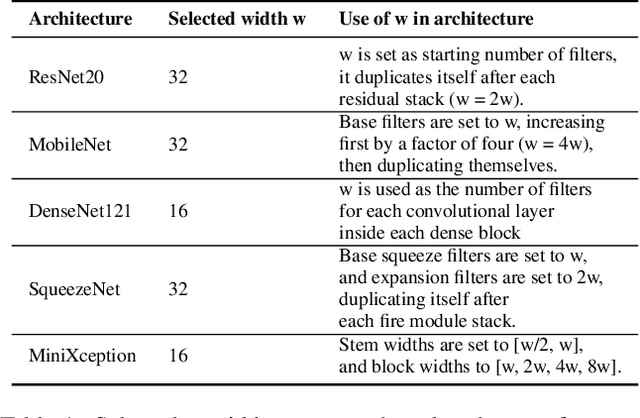
Machine learning and neural networks are now ubiquitous in sonar perception, but it lags behind the computer vision field due to the lack of data and pre-trained models specifically for sonar images. In this paper we present the Marine Debris Turntable dataset and produce pre-trained neural networks trained on this dataset, meant to fill the gap of missing pre-trained models for sonar images. We train Resnet 20, MobileNets, DenseNet121, SqueezeNet, MiniXception, and an Autoencoder, over several input image sizes, from 32 x 32 to 96 x 96, on the Marine Debris turntable dataset. We evaluate these models using transfer learning for low-shot classification in the Marine Debris Watertank and another dataset captured using a Gemini 720i sonar. Our results show that in both datasets the pre-trained models produce good features that allow good classification accuracy with low samples (10-30 samples per class). The Gemini dataset validates that the features transfer to other kinds of sonar sensors. We expect that the community benefits from the public release of our pre-trained models and the turntable dataset.
Speaker Fluency Level Classification Using Machine Learning Techniques
Aug 31, 2018



Level assessment for foreign language students is necessary for putting them in the right level group, furthermore, interviewing students is a very time-consuming task, so we propose to automate the evaluation of speaker fluency level by implementing machine learning techniques. This work presents an audio processing system capable of classifying the level of fluency of non-native English speakers using five different machine learning models. As a first step, we have built our own dataset, which consists of labeled audio conversations in English between people ranging in different fluency domains/classes (low, intermediate, high). We segment the audio conversations into 5s non-overlapped audio clips to perform feature extraction on them. We start by extracting Mel cepstral coefficients from the audios, selecting 20 coefficients is an appropriate quantity for our data. We thereafter extracted zero-crossing rate, root mean square energy and spectral flux features, proving that this improves model performance. Out of a total of 1424 audio segments, with 70% training data and 30% test data, one of our trained models (support vector machine) achieved a classification accuracy of 94.39%, whereas the other four models passed an 89% classification accuracy threshold.