 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlzheimers Dementia Detection using Acoustic & Linguistic features and Pre-Trained BERT
Sep 24, 2021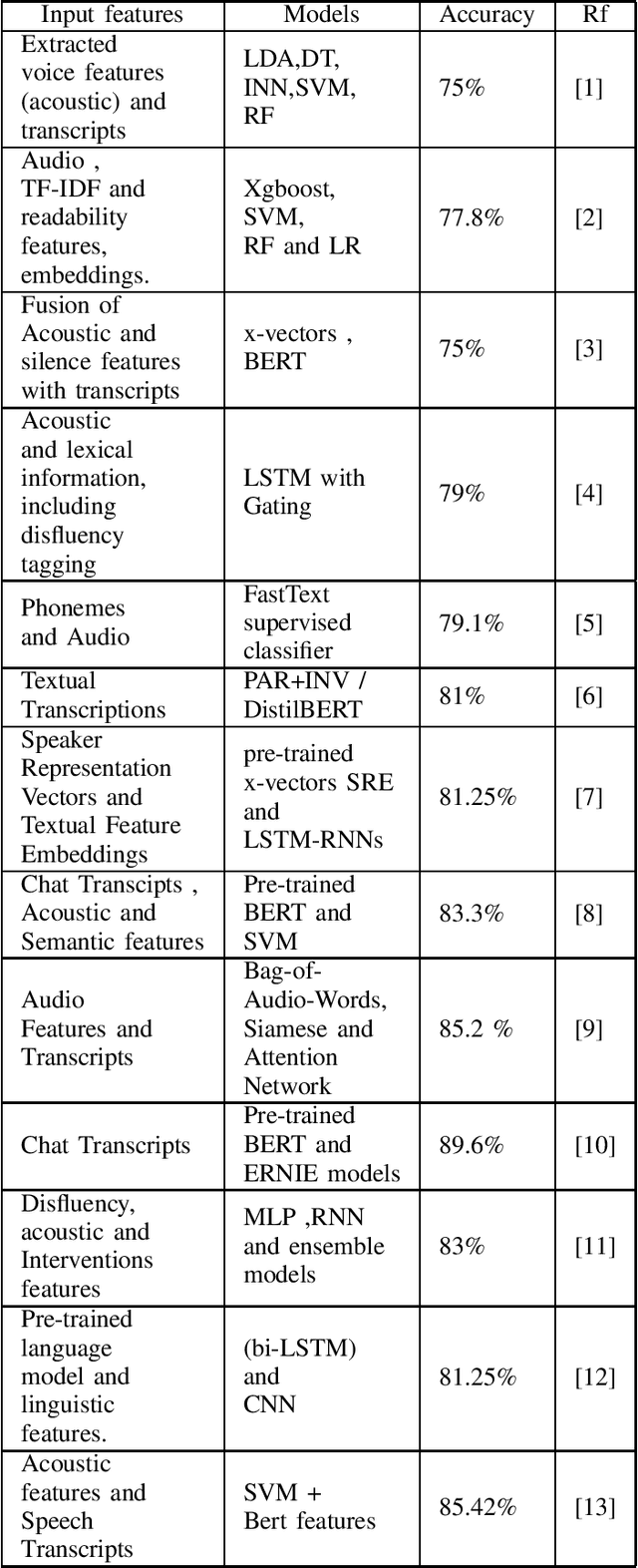
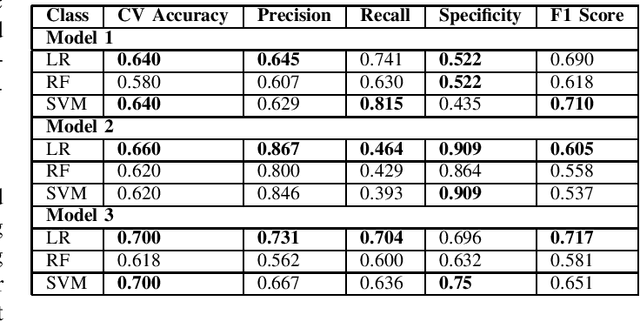
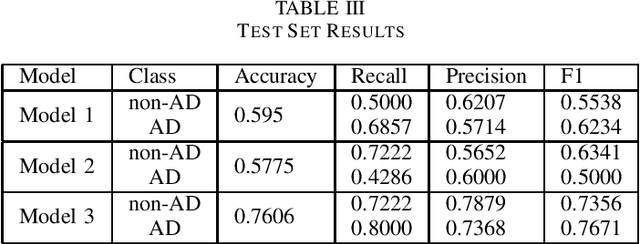
Alzheimers disease is a fatal progressive brain disorder that worsens with time. It is high time we have inexpensive and quick clinical diagnostic techniques for early detection and care. In previous studies, various Machine Learning techniques and Pre-trained Deep Learning models have been used in conjunction with the extraction of various acoustic and linguistic features. Our study focuses on three models for the classification task in the ADReSS (The Alzheimers Dementia Recognition through Spontaneous Speech) 2021 Challenge. We use the well-balanced dataset provided by the ADReSS Challenge for training and validating our models. Model 1 uses various acoustic features from the eGeMAPs feature-set, Model 2 uses various linguistic features that we generated from auto-generated transcripts and Model 3 uses the auto-generated transcripts directly to extract features using a Pre-trained BERT and TF-IDF. These models are described in detail in the models section.