 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Global-Local Approximation Framework for Large-Scale Gaussian Process Modeling
May 17, 2023In this work, we propose a novel framework for large-scale Gaussian process (GP) modeling. Contrary to the global, and local approximations proposed in the literature to address the computational bottleneck with exact GP modeling, we employ a combined global-local approach in building the approximation. Our framework uses a subset-of-data approach where the subset is a union of a set of global points designed to capture the global trend in the data, and a set of local points specific to a given testing location to capture the local trend around the testing location. The correlation function is also modeled as a combination of a global, and a local kernel. The performance of our framework, which we refer to as TwinGP, is on par or better than the state-of-the-art GP modeling methods at a fraction of their computational cost.
Data Twinning
Oct 06, 2021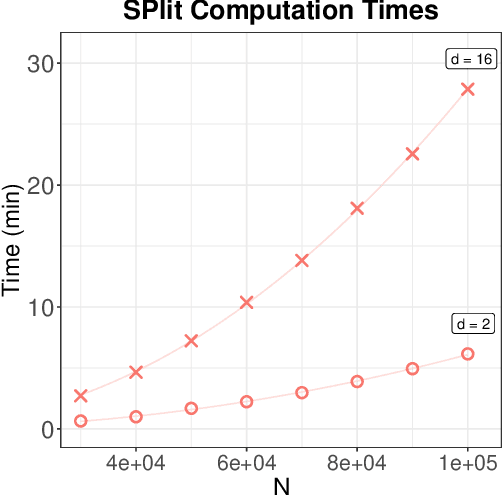
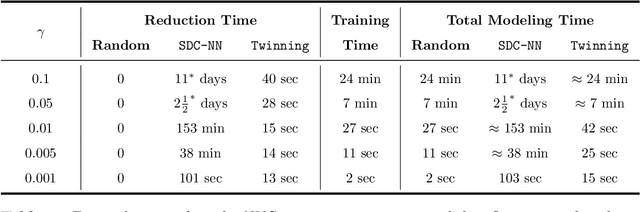
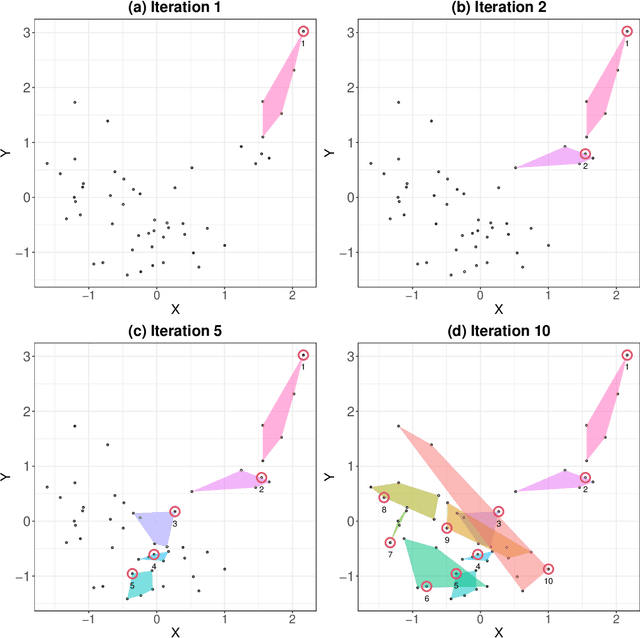
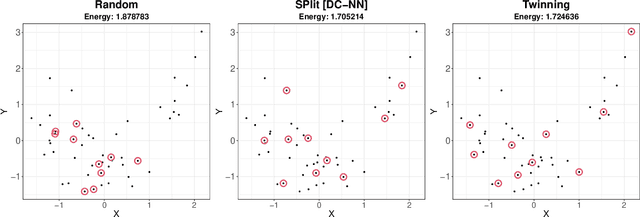
In this work, we develop a method named Twinning, for partitioning a dataset into statistically similar twin sets. Twinning is based on SPlit, a recently proposed model-independent method for optimally splitting a dataset into training and testing sets. Twinning is orders of magnitude faster than the SPlit algorithm, which makes it applicable to Big Data problems such as data compression. Twinning can also be used for generating multiple splits of a given dataset to aid divide-and-conquer procedures and $k$-fold cross validation.
SPlit: An Optimal Method for Data Splitting
Dec 20, 2020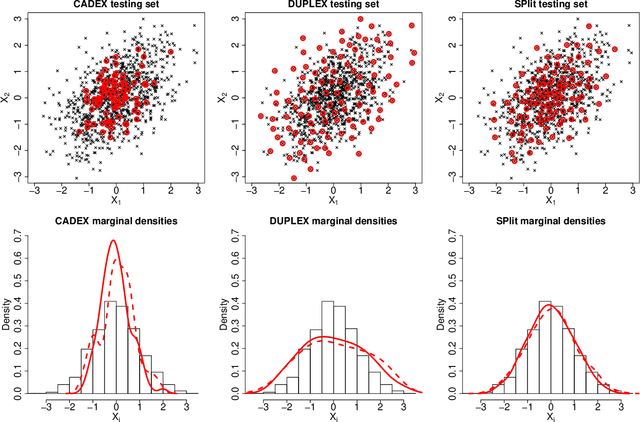
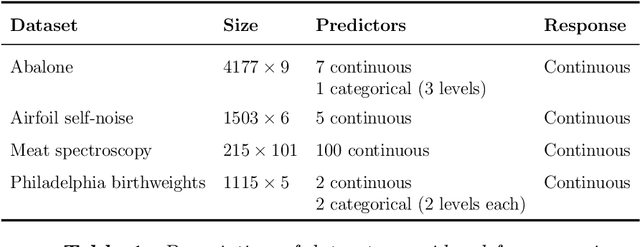
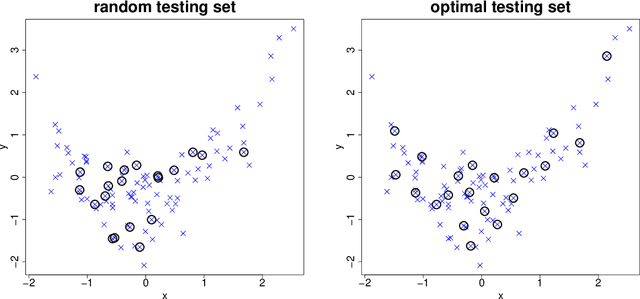
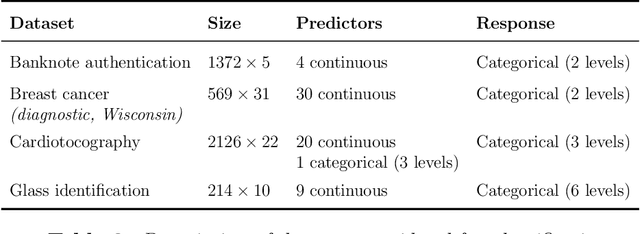
In this article we propose an optimal method referred to as SPlit for splitting a dataset into training and testing sets. SPlit is based on the method of Support Points (SP), which was initially developed for finding the optimal representative points of a continuous distribution. We adapt SP for subsampling from a dataset using a sequential nearest neighbor algorithm. We also extend SP to deal with categorical variables so that SPlit can be applied to both regression and classification problems. The implementation of SPlit on real datasets shows substantial improvement in the worst-case testing performance for several modeling methods compared to the commonly used random splitting procedure.