 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANER: Arabic and Arabizi Named Entity Recognition using Transformer-Based Approach
Aug 28, 2023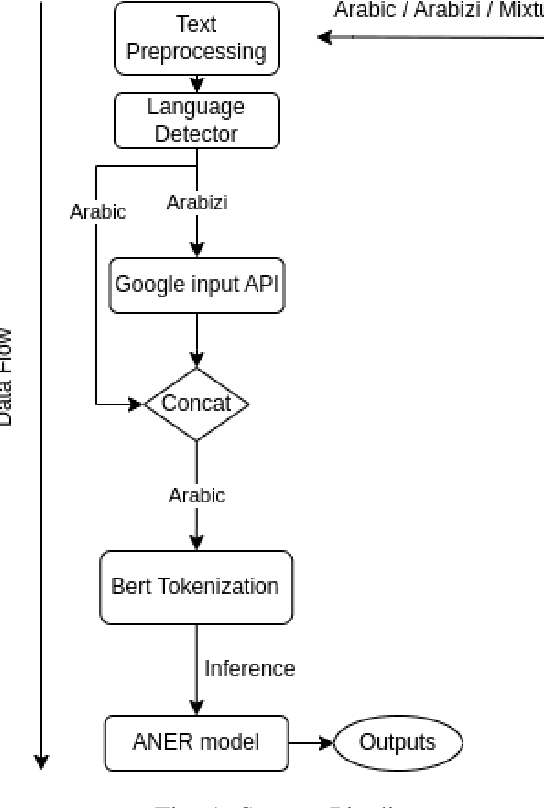
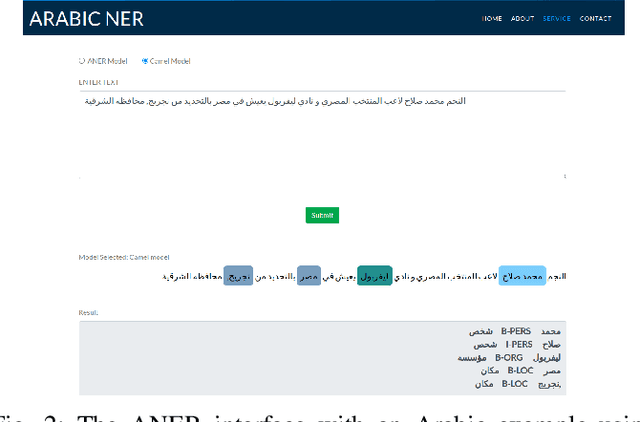
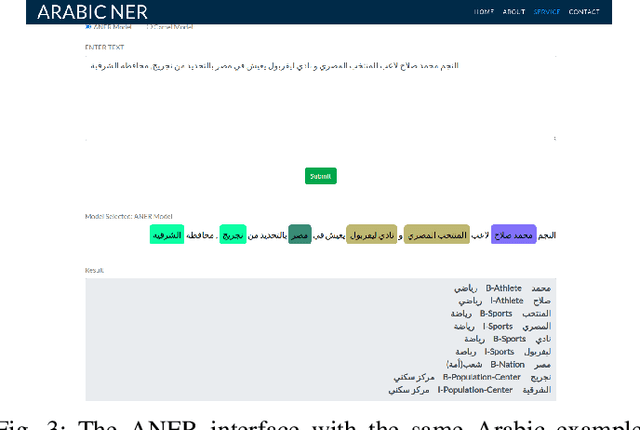
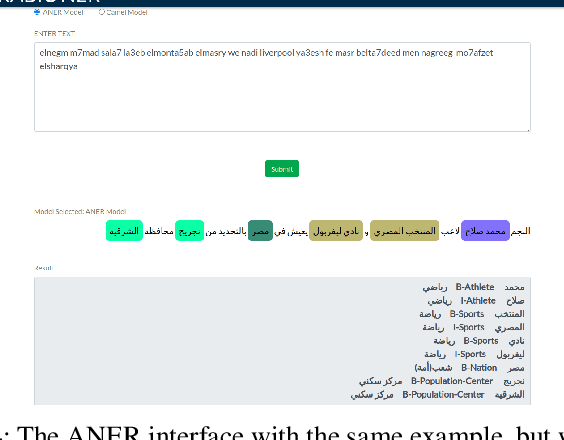
One of the main tasks of Natural Language Processing (NLP), is Named Entity Recognition (NER). It is used in many applications and also can be used as an intermediate step for other tasks. We present ANER, a web-based named entity recognizer for the Arabic, and Arabizi languages. The model is built upon BERT, which is a transformer-based encoder. It can recognize 50 different entity classes, covering various fields. We trained our model on the WikiFANE\_Gold dataset which consists of Wikipedia articles. We achieved an F1 score of 88.7\%, which beats CAMeL Tools' F1 score of 83\% on the ANERcorp dataset, which has only 4 classes. We also got an F1 score of 77.7\% on the NewsFANE\_Gold dataset which contains out-of-domain data from News articles. The system is deployed on a user-friendly web interface that accepts users' inputs in Arabic, or Arabizi. It allows users to explore the entities in the text by highlighting them. It can also direct users to get information about entities through Wikipedia directly. We added the ability to do NER using our model, or CAMeL Tools' model through our website. ANER is publicly accessible at \url{http://www.aner.online}. We also deployed our model on HuggingFace at https://huggingface.co/boda/ANER, to allow developers to test and use it.
Egyptian Dialect Stopword List Generation from Social Network Data
Apr 13, 2015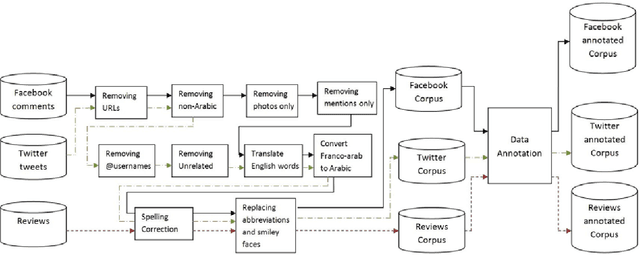
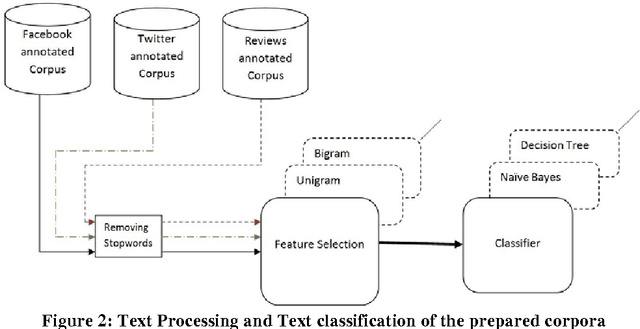
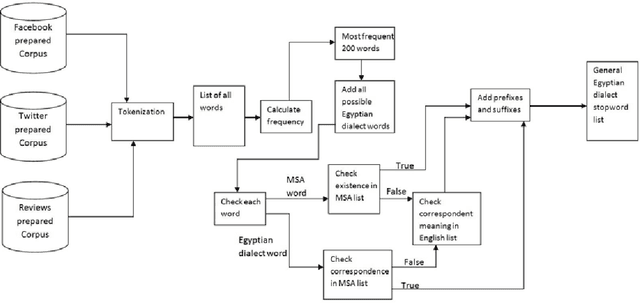
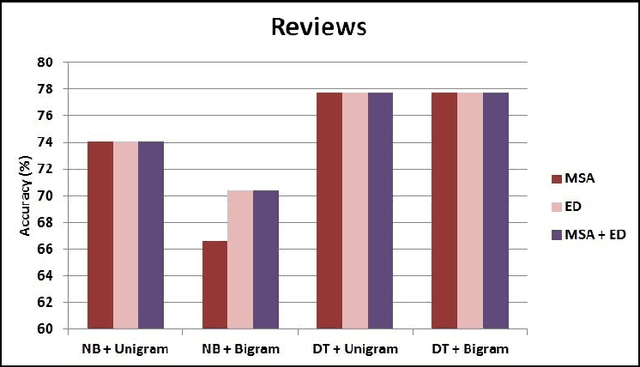
This paper proposes a methodology for generating a stopword list from online social network (OSN) corpora in Egyptian Dialect(ED). The aim of the paper is to investigate the effect of removingED stopwords on the Sentiment Analysis (SA) task. The stopwords lists generated before were on Modern Standard Arabic (MSA) which is not the common language used in OSN. We have generated a stopword list of Egyptian dialect to be used with the OSN corpora. We compare the efficiency of text classification when using the generated list along with previously generated lists of MSA and combining the Egyptian dialect list with the MSA list. The text classification was performed using Na\"ive Bayes and Decision Tree classifiers and two feature selection approaches, unigram and bigram. The experiments show that removing ED stopwords give better performance than using lists of MSA stopwords only.
Corpora Preparation and Stopword List Generation for Arabic data in Social Network
Oct 05, 2014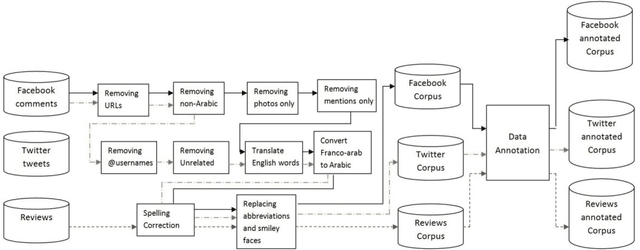

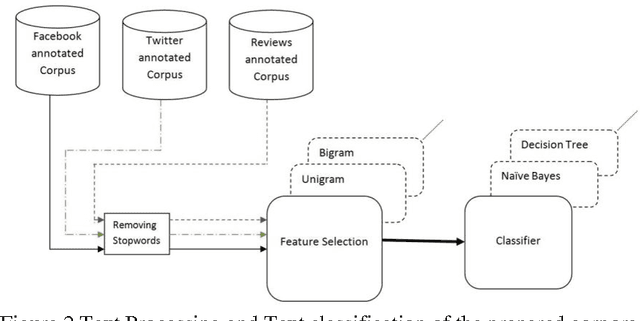
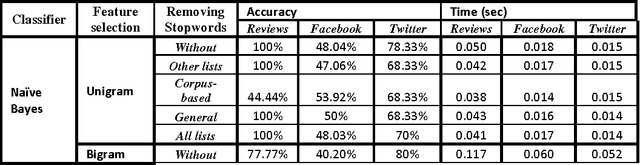
This paper proposes a methodology to prepare corpora in Arabic language from online social network (OSN) and review site for Sentiment Analysis (SA) task. The paper also proposes a methodology for generating a stopword list from the prepared corpora. The aim of the paper is to investigate the effect of removing stopwords on the SA task. The problem is that the stopwords lists generated before were on Modern Standard Arabic (MSA) which is not the common language used in OSN. We have generated a stopword list of Egyptian dialect and a corpus-based list to be used with the OSN corpora. We compare the efficiency of text classification when using the generated lists along with previously generated lists of MSA and combining the Egyptian dialect list with the MSA list. The text classification was performed using Na\"ive Bayes and Decision Tree classifiers and two feature selection approaches, unigrams and bigram. The experiments show that the general lists containing the Egyptian dialects words give better performance than using lists of MSA stopwords only.
Cross-Language Personal Name Mapping
May 24, 2014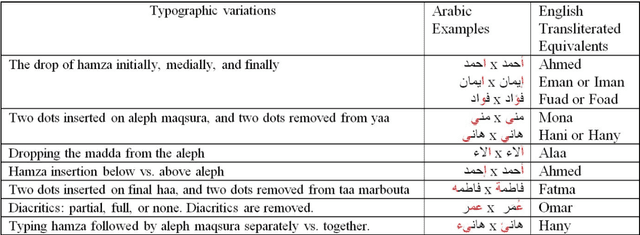
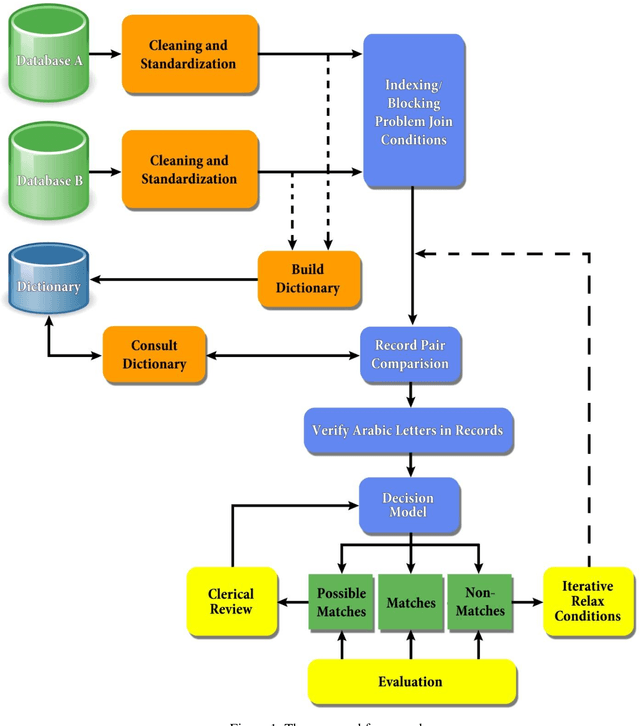


Name matching between multiple natural languages is an important step in cross-enterprise integration applications and data mining. It is difficult to decide whether or not two syntactic values (names) from two heterogeneous data sources are alternative designation of the same semantic entity (person), this process becomes more difficult with Arabic language due to several factors including spelling and pronunciation variation, dialects and special vowel and consonant distinction and other linguistic characteristics. This paper proposes a new framework for name matching between the Arabic language and other languages. The framework uses a dictionary based on a new proposed version of the Soundex algorithm to encapsulate the recognition of special features of Arabic names. The framework proposes a new proximity matching algorithm to suit the high importance of order sensitivity in Arabic name matching. New performance evaluation metrics are proposed as well. The framework is implemented and verified empirically in several case studies demonstrating substantial improvements compared to other well-known techniques found in literature.