 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpora Preparation and Stopword List Generation for Arabic data in Social Network
Paper and Code
Oct 05, 2014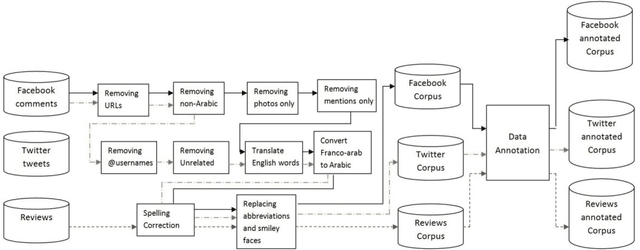

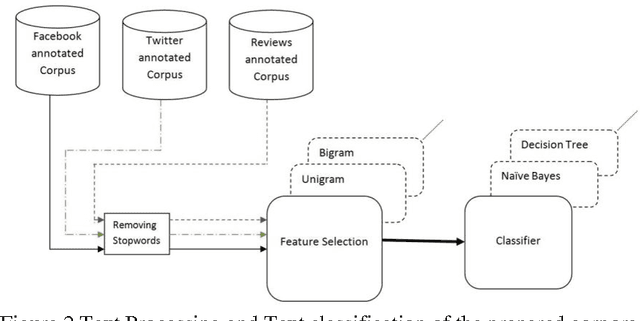
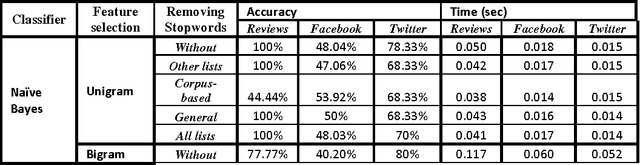
This paper proposes a methodology to prepare corpora in Arabic language from online social network (OSN) and review site for Sentiment Analysis (SA) task. The paper also proposes a methodology for generating a stopword list from the prepared corpora. The aim of the paper is to investigate the effect of removing stopwords on the SA task. The problem is that the stopwords lists generated before were on Modern Standard Arabic (MSA) which is not the common language used in OSN. We have generated a stopword list of Egyptian dialect and a corpus-based list to be used with the OSN corpora. We compare the efficiency of text classification when using the generated lists along with previously generated lists of MSA and combining the Egyptian dialect list with the MSA list. The text classification was performed using Na\"ive Bayes and Decision Tree classifiers and two feature selection approaches, unigrams and bigram. The experiments show that the general lists containing the Egyptian dialects words give better performance than using lists of MSA stopwords only.