 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre LLMs Good Cryptic Crossword Solvers?
Mar 15, 2024Cryptic crosswords are puzzles that rely not only on general knowledge but also on the solver's ability to manipulate language on different levels and deal with various types of wordplay. Previous research suggests that solving such puzzles is a challenge even for modern NLP models. However, the abilities of large language models (LLMs) have not yet been tested on this task. In this paper, we establish the benchmark results for three popular LLMs -- LLaMA2, Mistral, and ChatGPT -- showing that their performance on this task is still far from that of humans.
ANER: Arabic and Arabizi Named Entity Recognition using Transformer-Based Approach
Aug 28, 2023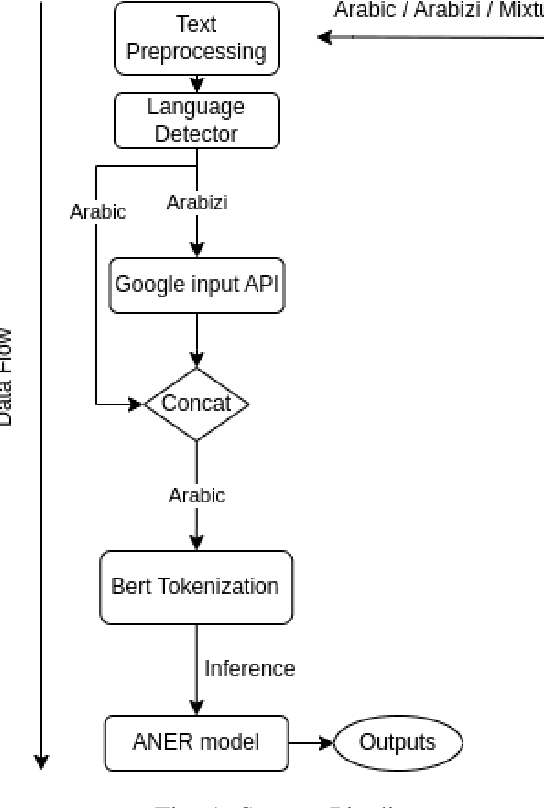
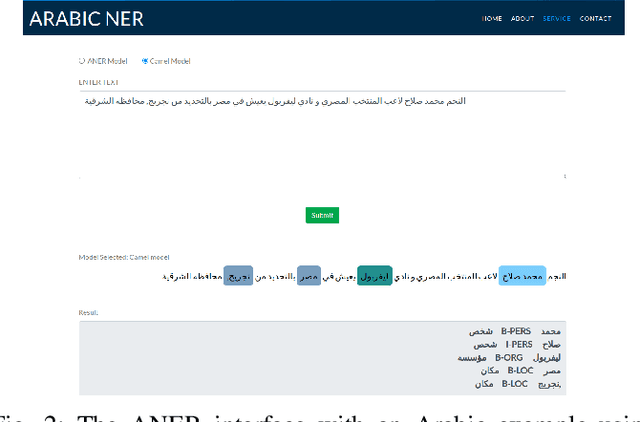
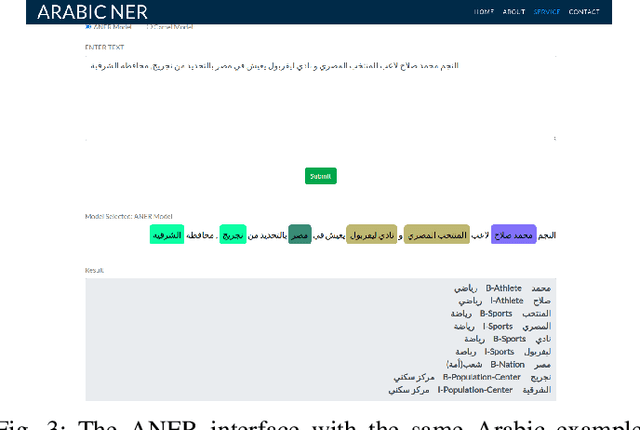
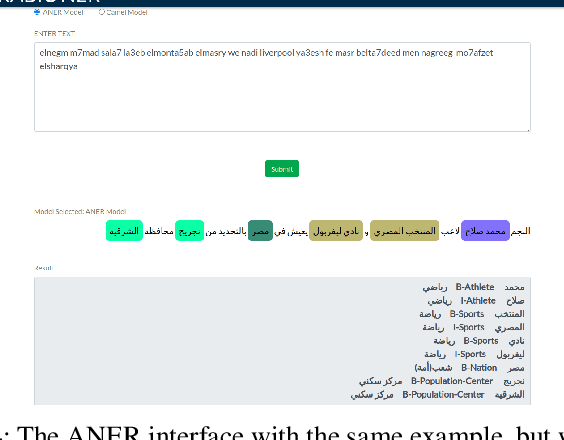
One of the main tasks of Natural Language Processing (NLP), is Named Entity Recognition (NER). It is used in many applications and also can be used as an intermediate step for other tasks. We present ANER, a web-based named entity recognizer for the Arabic, and Arabizi languages. The model is built upon BERT, which is a transformer-based encoder. It can recognize 50 different entity classes, covering various fields. We trained our model on the WikiFANE\_Gold dataset which consists of Wikipedia articles. We achieved an F1 score of 88.7\%, which beats CAMeL Tools' F1 score of 83\% on the ANERcorp dataset, which has only 4 classes. We also got an F1 score of 77.7\% on the NewsFANE\_Gold dataset which contains out-of-domain data from News articles. The system is deployed on a user-friendly web interface that accepts users' inputs in Arabic, or Arabizi. It allows users to explore the entities in the text by highlighting them. It can also direct users to get information about entities through Wikipedia directly. We added the ability to do NER using our model, or CAMeL Tools' model through our website. ANER is publicly accessible at \url{http://www.aner.online}. We also deployed our model on HuggingFace at https://huggingface.co/boda/ANER, to allow developers to test and use it.