 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA superpixel-driven deep learning approach for the analysis of dermatological wounds
Sep 20, 2019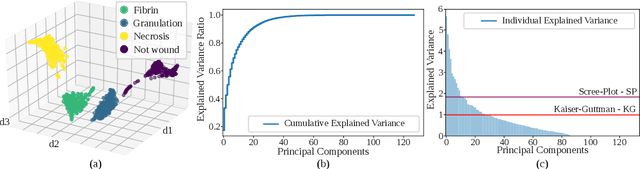
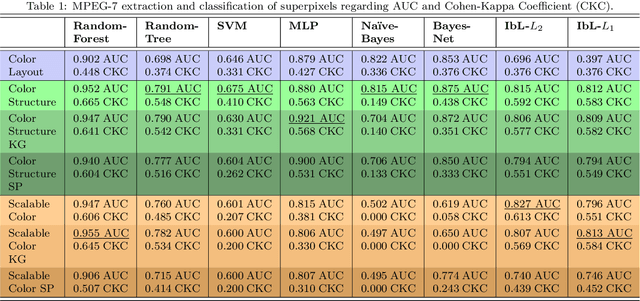
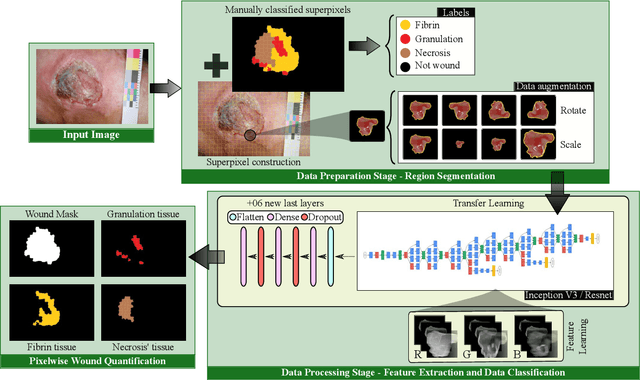
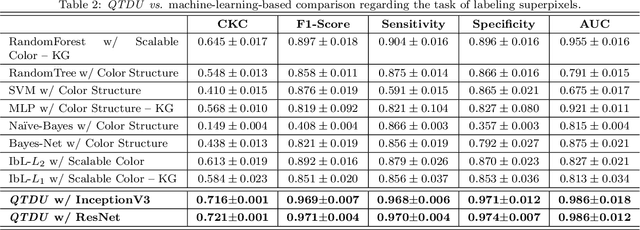
Background. The image-based identification of distinct tissues within dermatological wounds enhances patients' care since it requires no intrusive evaluations. This manuscript presents an approach, we named QTDU, that combines deep learning models with superpixel-driven segmentation methods for assessing the quality of tissues from dermatological ulcers. Method. QTDU consists of a three-stage pipeline for the obtaining of ulcer segmentation, tissues' labeling, and wounded area quantification. We set up our approach by using a real and annotated set of dermatological ulcers for training several deep learning models to the identification of ulcered superpixels. Results. Empirical evaluations on 179,572 superpixels divided into four classes showed QTDU accurately spot wounded tissues (AUC = 0.986, sensitivity = 0.97, and specificity = 0.974) and outperformed machine-learning approaches in up to 8.2% regarding F1-Score through fine-tuning of a ResNet-based model. Last, but not least, experimental evaluations also showed QTDU correctly quantified wounded tissue areas within a 0.089 Mean Absolute Error ratio. Conclusions. Results indicate QTDU effectiveness for both tissue segmentation and wounded area quantification tasks. When compared to existing machine-learning approaches, the combination of superpixels and deep learning models outperformed the competitors within strong significant levels.
3DBGrowth: volumetric vertebrae segmentation and reconstruction in magnetic resonance imaging
Jul 08, 2019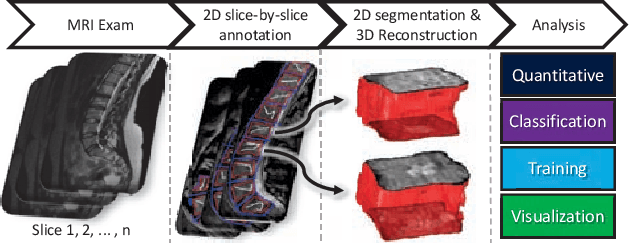
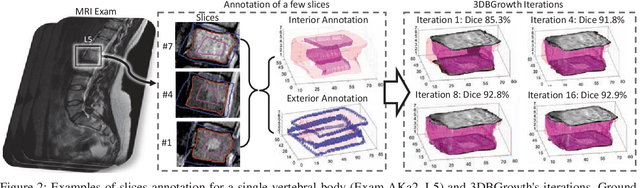
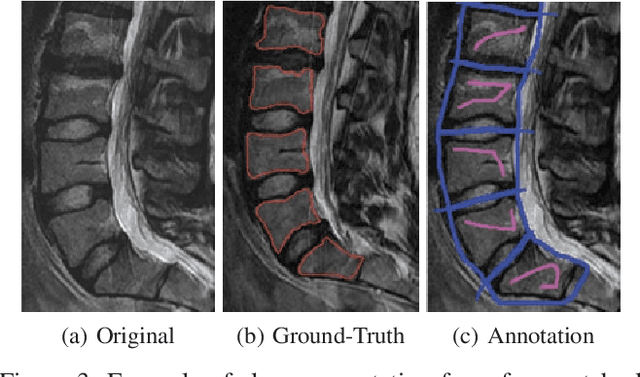
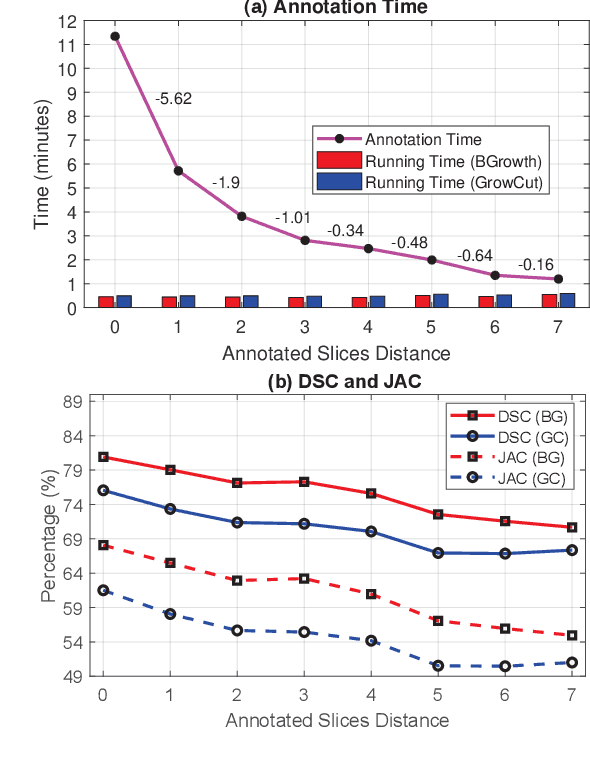
Segmentation of medical images is critical for making several processes of analysis and classification more reliable. With the growing number of people presenting back pain and related problems, the semi-automatic segmentation and 3D reconstruction of vertebral bodies became even more important to support decision making. A 3D reconstruction allows a fast and objective analysis of each vertebrae condition, which may play a major role in surgical planning and evaluation of suitable treatments. In this paper, we propose 3DBGrowth, which develops a 3D reconstruction over the efficient Balanced Growth method for 2D images. We also take advantage of the slope coefficient from the annotation time to reduce the total number of annotated slices, reducing the time spent on manual annotation. We show experimental results on a representative dataset with 17 MRI exams demonstrating that our approach significantly outperforms the competitors and, on average, only 37% of the total slices with vertebral body content must be annotated without losing performance/accuracy. Compared to the state-of-the-art methods, we have achieved a Dice Score gain of over 5% with comparable processing time. Moreover, 3DBGrowth works well with imprecise seed points, which reduces the time spent on manual annotation by the specialist.
* This is a pre-print of an article published in Computer-Based Medical Systems. The final authenticated version is available online at: https://doi.org/10.1109/CBMS.2019.00091
BGrowth: an efficient approach for the segmentation of vertebral compression fractures in magnetic resonance imaging
Jun 25, 2019


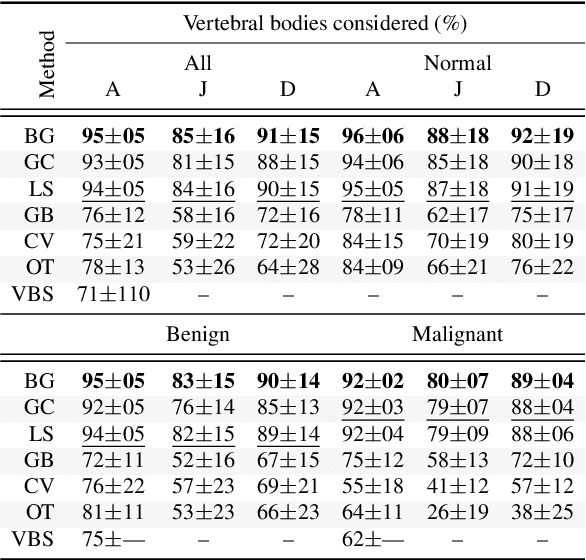
Segmentation of medical images is a critical issue: several process of analysis and classification rely on this segmentation. With the growing number of people presenting back pain and problems related to it, the automatic or semi-automatic segmentation of fractured vertebral bodies became a challenging task. In general, those fractures present several regions with non-homogeneous intensities and the dark regions are quite similar to the structures nearby. Aimed at overriding this challenge, in this paper we present a semi-automatic segmentation method, called Balanced Growth (BGrowth). The experimental results on a dataset with 102 crushed and 89 normal vertebrae show that our approach significantly outperforms well-known methods from the literature. We have achieved an accuracy up to 95% while keeping acceptable processing time performance, that is equivalent to the state-of-the-artmethods. Moreover, BGrowth presents the best results even with a rough (sloppy) manual annotation (seed points).
* This is a pre-print of an article published in Symposium on Applied Computing. The final authenticated version is available online at https://doi.org/10.1145/3297280.3299728
BoWFire: Detection of Fire in Still Images by Integrating Pixel Color and Texture Analysis
Jun 10, 2015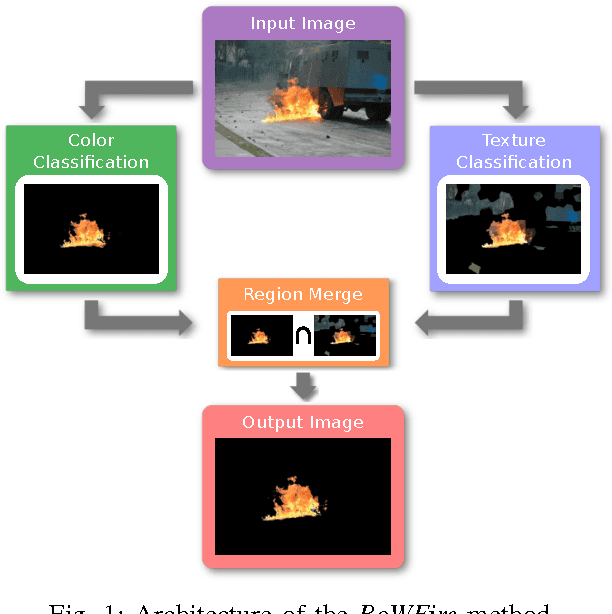

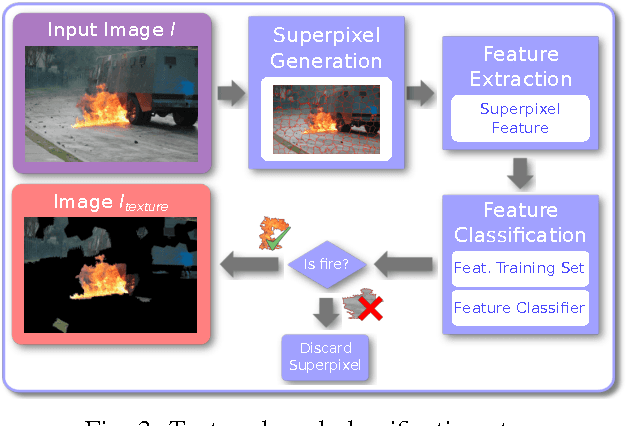

Emergency events involving fire are potentially harmful, demanding a fast and precise decision making. The use of crowdsourcing image and videos on crisis management systems can aid in these situations by providing more information than verbal/textual descriptions. Due to the usual high volume of data, automatic solutions need to discard non-relevant content without losing relevant information. There are several methods for fire detection on video using color-based models. However, they are not adequate for still image processing, because they can suffer on high false-positive results. These methods also suffer from parameters with little physical meaning, which makes fine tuning a difficult task. In this context, we propose a novel fire detection method for still images that uses classification based on color features combined with texture classification on superpixel regions. Our method uses a reduced number of parameters if compared to previous works, easing the process of fine tuning the method. Results show the effectiveness of our method of reducing false-positives while its precision remains compatible with the state-of-the-art methods.