 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid quantification of COVID-19 pneumonia burden from computed tomography with convolutional LSTM networks
Mar 31, 2021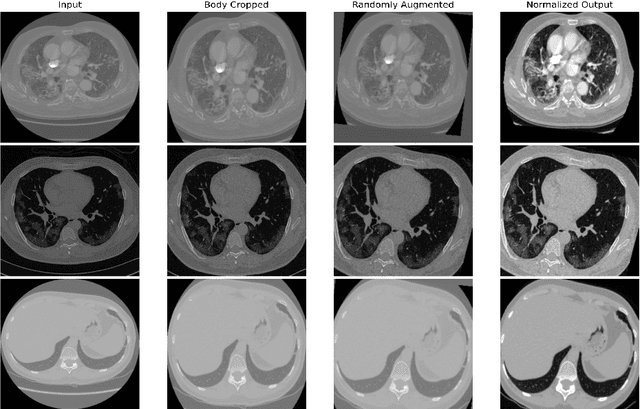
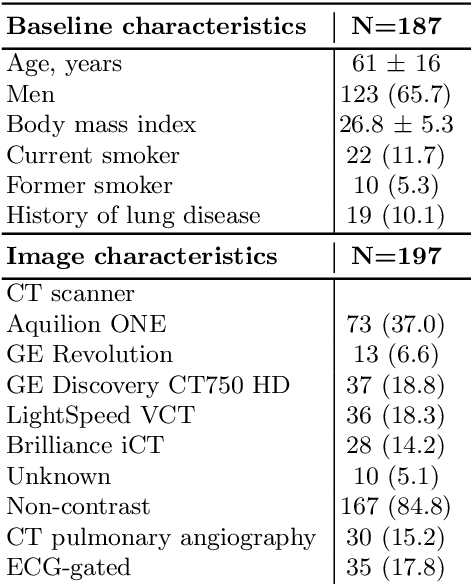
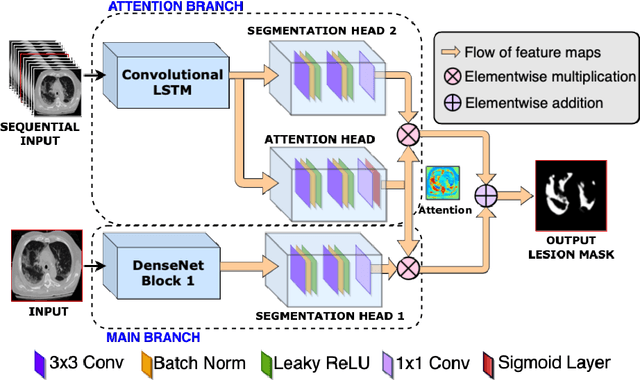
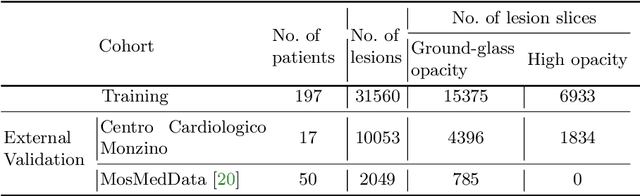
Quantitative lung measures derived from computed tomography (CT) have been demonstrated to improve prognostication in coronavirus disease (COVID-19) patients, but are not part of the clinical routine since required manual segmentation of lung lesions is prohibitively time-consuming. We propose a new fully automated deep learning framework for rapid quantification and differentiation between lung lesions in COVID-19 pneumonia from both contrast and non-contrast CT images using convolutional Long Short-Term Memory (ConvLSTM) networks. Utilizing the expert annotations, model training was performed 5 times with separate hold-out sets using 5-fold cross-validation to segment ground-glass opacity and high opacity (including consolidation and pleural effusion). The performance of the method was evaluated on CT data sets from 197 patients with positive reverse transcription polymerase chain reaction test result for SARS-CoV-2. Strong agreement between expert manual and automatic segmentation was obtained for lung lesions with a Dice score coefficient of 0.876 $\pm$ 0.005; excellent correlations of 0.978 and 0.981 for ground-glass opacity and high opacity volumes. In the external validation set of 67 patients, there was dice score coefficient of 0.767 $\pm$ 0.009 as well as excellent correlations of 0.989 and 0.996 for ground-glass opacity and high opacity volumes. Computations for a CT scan comprising 120 slices were performed under 2 seconds on a personal computer equipped with NVIDIA Titan RTX graphics processing unit. Therefore, our deep learning-based method allows rapid fully-automated quantitative measurement of pneumonia burden from CT and may generate results with an accuracy similar to the expert readers.
Two-branch Recurrent Network for Isolating Deepfakes in Videos
Sep 04, 2020
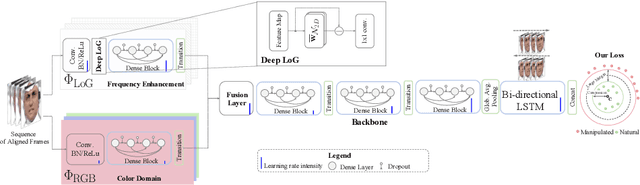


The current spike of hyper-realistic faces artificially generated using deepfakes calls for media forensics solutions that are tailored to video streams and work reliably with a low false alarm rate at the video level. We present a method for deepfake detection based on a two-branch network structure that isolates digitally manipulated faces by learning to amplify artifacts while suppressing the high-level face content. Unlike current methods that extract spatial frequencies as a preprocessing step, we propose a two-branch structure: one branch propagates the original information, while the other branch suppresses the face content yet amplifies multi-band frequencies using a Laplacian of Gaussian (LoG) as a bottleneck layer. To better isolate manipulated faces, we derive a novel cost function that, unlike regular classification, compresses the variability of natural faces and pushes away the unrealistic facial samples in the feature space. Our two novel components show promising results on the FaceForensics++, Celeb-DF, and Facebook's DFDC preview benchmarks, when compared to prior work. We then offer a full, detailed ablation study of our network architecture and cost function. Finally, although the bar is still high to get very remarkable figures at a very low false alarm rate, our study shows that we can achieve good video-level performance when cross-testing in terms of video-level AUC.