 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauging Overprecision in LLMs: An Empirical Study
Apr 16, 2025



Recently, overconfidence in large language models (LLMs) has garnered considerable attention due to its fundamental importance in quantifying the trustworthiness of LLM generation. However, existing approaches prompt the \textit{black box LLMs} to produce their confidence (\textit{verbalized confidence}), which can be subject to many biases and hallucinations. Inspired by a different aspect of overconfidence in cognitive science called \textit{overprecision}, we designed a framework for its study in black box LLMs. This framework contains three main phases: 1) generation, 2) refinement and 3) evaluation. In the generation phase we prompt the LLM to generate answers to numerical questions in the form of intervals with a certain level of confidence. This confidence level is imposed in the prompt and not required for the LLM to generate as in previous approaches. We use various prompting techniques and use the same prompt multiple times to gauge the effects of randomness in the generation process. In the refinement phase, answers from the previous phase are refined to generate better answers. The LLM answers are evaluated and studied in the evaluation phase to understand its internal workings. This study allowed us to gain various insights into LLM overprecision: 1) LLMs are highly uncalibrated for numerical tasks 2) {\color{blue}there is no correlation between the length of the interval and the imposed confidence level, which can be symptomatic of a a) lack of understanding of the concept of confidence or b) inability to adjust self-confidence by following instructions}, {\color{blue}3)} LLM numerical precision differs depending on the task, scale of answer and prompting technique {\color{blue}4) Refinement of answers doesn't improve precision in most cases}. We believe this study offers new perspectives on LLM overconfidence and serves as a strong baseline for overprecision in LLMs.
AsthmaBot: Multi-modal, Multi-Lingual Retrieval Augmented Generation For Asthma Patient Support
Sep 24, 2024



Asthma rates have risen globally, driven by environmental and lifestyle factors. Access to immediate medical care is limited, particularly in developing countries, necessitating automated support systems. Large Language Models like ChatGPT (Chat Generative Pre-trained Transformer) and Gemini have advanced natural language processing in general and question answering in particular, however, they are prone to producing factually incorrect responses (i.e. hallucinations). Retrieval-augmented generation systems, integrating curated documents, can improve large language models' performance and reduce the incidence of hallucination. We introduce AsthmaBot, a multi-lingual, multi-modal retrieval-augmented generation system for asthma support. Evaluation of an asthma-related frequently asked questions dataset shows AsthmaBot's efficacy. AsthmaBot has an added interactive and intuitive interface that integrates different data modalities (text, images, videos) to make it accessible to the larger public. AsthmaBot is available online via \url{asthmabot.datanets.org}.
KG-NSF: Knowledge Graph Completion with a Negative-Sample-Free Approach
Jul 29, 2022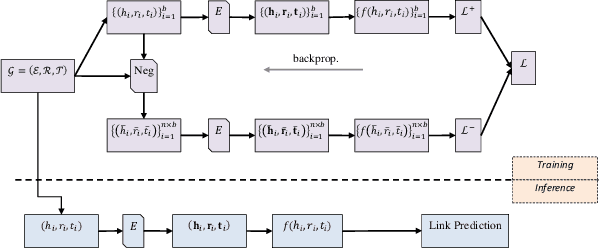
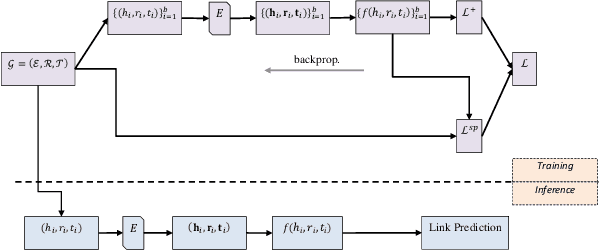
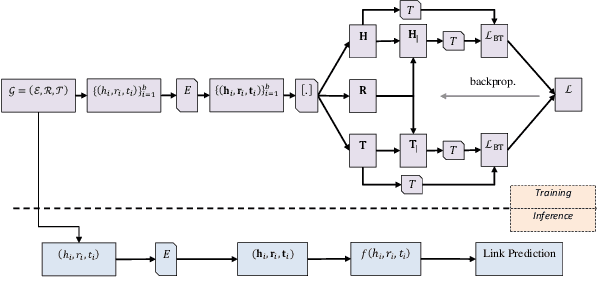
Knowledge Graph (KG) completion is an important task that greatly benefits knowledge discovery in many fields (e.g. biomedical research). In recent years, learning KG embeddings to perform this task has received considerable attention. Despite the success of KG embedding methods, they predominantly use negative sampling, resulting in increased computational complexity as well as biased predictions due to the closed world assumption. To overcome these limitations, we propose \textbf{KG-NSF}, a negative sampling-free framework for learning KG embeddings based on the cross-correlation matrices of embedding vectors. It is shown that the proposed method achieves comparable link prediction performance to negative sampling-based methods while converging much faster.