 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental limits for weighted empirical approximations of tilted distributions
Dec 30, 2025Consider the task of generating samples from a tilted distribution of a random vector whose underlying distribution is unknown, but samples from it are available. This finds applications in fields such as finance and climate science, and in rare event simulation. In this article, we discuss the asymptotic efficiency of a self-normalized importance sampler of the tilted distribution. We provide a sharp characterization of its accuracy, given the number of samples and the degree of tilt. Our findings reveal a surprising dichotomy: while the number of samples needed to accurately tilt a bounded random vector increases polynomially in the tilt amount, it increases at a super polynomial rate for unbounded distributions.
Discriminative Learning via Adaptive Questioning
Apr 11, 2020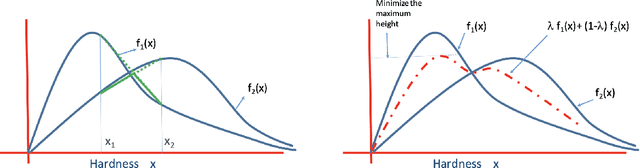
We consider the problem of designing an adaptive sequence of questions that optimally classify a candidate's ability into one of several categories or discriminative grades. A candidate's ability is modeled as an unknown parameter, which, together with the difficulty of the question asked, determines the likelihood with which s/he is able to answer a question correctly. The learning algorithm is only able to observe these noisy responses to its queries. We consider this problem from a fixed confidence-based $\delta$-correct framework, that in our setting seeks to arrive at the correct ability discrimination at the fastest possible rate while guaranteeing that the probability of error is less than a pre-specified and small $\delta$. In this setting we develop lower bounds on any sequential questioning strategy and develop geometrical insights into the problem structure both from primal and dual formulation. In addition, we arrive at algorithms that essentially match these lower bounds. Our key conclusions are that, asymptotically, any candidate needs to be asked questions at most at two (candidate ability-specific) levels, although, in a reasonably general framework, questions need to be asked only at a single level. Further, and interestingly, the problem structure facilitates endogenous exploration, so there is no need for a separately designed exploration stage in the algorithm.