 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuCoS: Efficient Drug Target Discovery via Multi Context Aware Sampling in Knowledge Graphs
Mar 11, 2025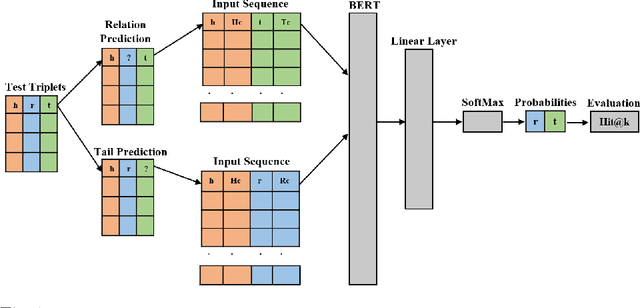
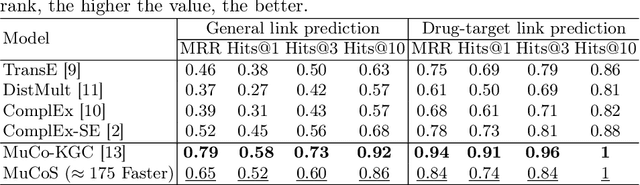
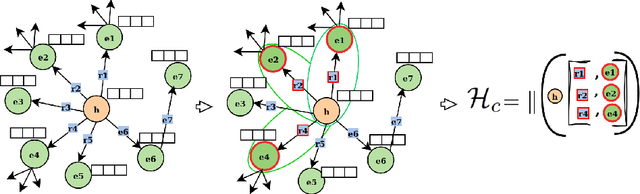

Accurate prediction of drug target interactions is critical for accelerating drug discovery and elucidating complex biological mechanisms. In this work, we frame drug target prediction as a link prediction task on heterogeneous biomedical knowledge graphs (KG) that integrate drugs, proteins, diseases, pathways, and other relevant entities. Conventional KG embedding methods such as TransE and ComplEx SE are hindered by their reliance on computationally intensive negative sampling and their limited generalization to unseen drug target pairs. To address these challenges, we propose Multi Context Aware Sampling (MuCoS), a novel framework that prioritizes high-density neighbours to capture salient structural patterns and integrates these with contextual embeddings derived from BERT. By unifying structural and textual modalities and selectively sampling highly informative patterns, MuCoS circumvents the need for negative sampling, significantly reducing computational overhead while enhancing predictive accuracy for novel drug target associations and drug targets. Extensive experiments on the KEGG50k dataset demonstrate that MuCoS outperforms state-of-the-art baselines, achieving up to a 13\% improvement in mean reciprocal rank (MRR) in predicting any relation in the dataset and a 6\% improvement in dedicated drug target relation prediction.
A Contextualized BERT model for Knowledge Graph Completion
Dec 15, 2024Knowledge graphs (KGs) are valuable for representing structured, interconnected information across domains, enabling tasks like semantic search, recommendation systems and inference. A pertinent challenge with KGs, however, is that many entities (i.e., heads, tails) or relationships are unknown. Knowledge Graph Completion (KGC) addresses this by predicting these missing nodes or links, enhancing the graph's informational depth and utility. Traditional methods like TransE and ComplEx predict tail entities but struggle with unseen entities. Textual-based models leverage additional semantics but come with high computational costs, semantic inconsistencies, and data imbalance issues. Recent LLM-based models show improvement but overlook contextual information and rely heavily on entity descriptions. In this study, we introduce a contextualized BERT model for KGC that overcomes these limitations by utilizing the contextual information from neighbouring entities and relationships to predict tail entities. Our model eliminates the need for entity descriptions and negative triplet sampling, reducing computational demands while improving performance. Our model outperforms state-of-the-art methods on standard datasets, improving Hit@1 by 5.3% and 4.88% on FB15k-237 and WN18RR respectively, setting a new benchmark in KGC.
Defense against adversarial attacks on deep convolutional neural networks through nonlocal denoising
Jun 25, 2022
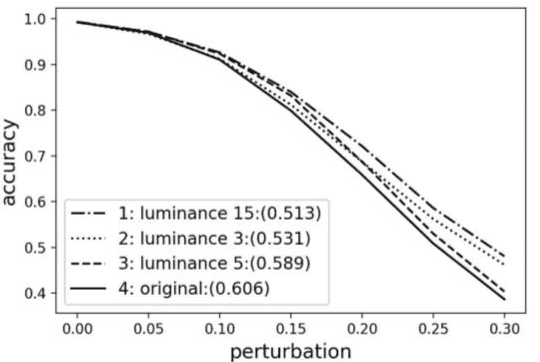
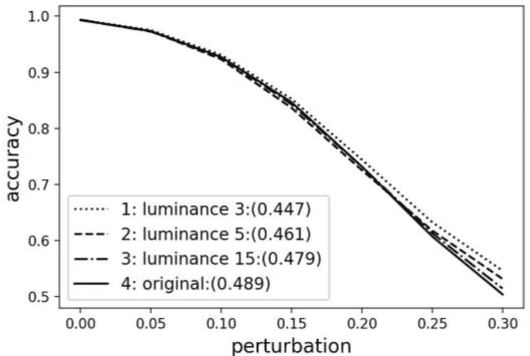
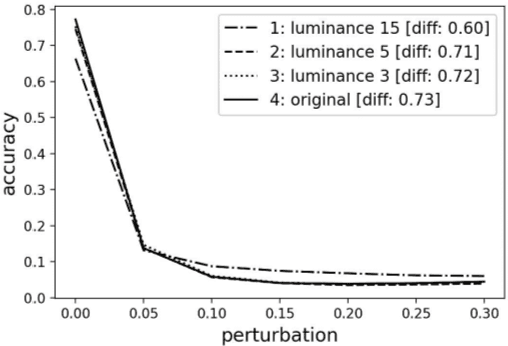
Despite substantial advances in network architecture performance, the susceptibility of adversarial attacks makes deep learning challenging to implement in safety-critical applications. This paper proposes a data-centric approach to addressing this problem. A nonlocal denoising method with different luminance values has been used to generate adversarial examples from the Modified National Institute of Standards and Technology database (MNIST) and Canadian Institute for Advanced Research (CIFAR-10) data sets. Under perturbation, the method provided absolute accuracy improvements of up to 9.3% in the MNIST data set and 13% in the CIFAR-10 data set. Training using transformed images with higher luminance values increases the robustness of the classifier. We have shown that transfer learning is disadvantageous for adversarial machine learning. The results indicate that simple adversarial examples can improve resilience and make deep learning easier to apply in various applications.
Transfer learning for cancer diagnosis in histopathological images
Dec 31, 2021
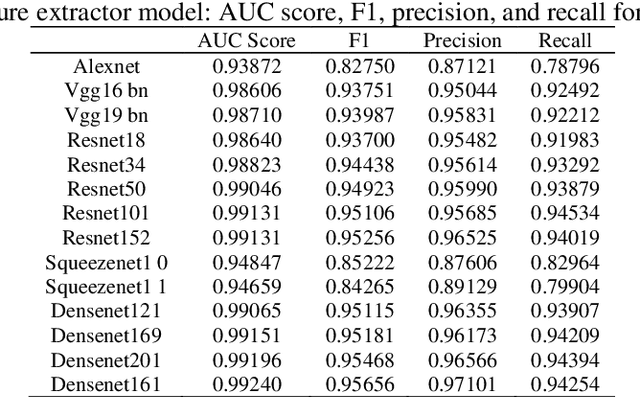
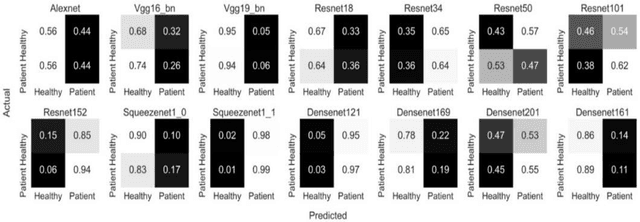
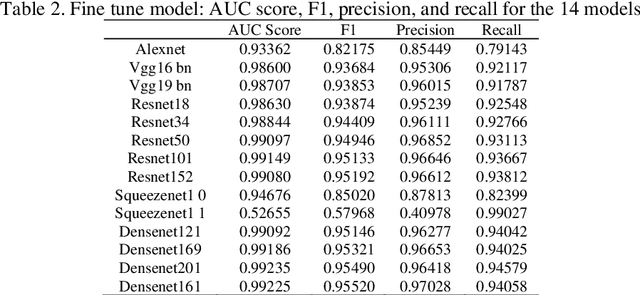
Transfer learning allows us to exploit knowledge gained from one task to assist in solving another but relevant task. In modern computer vision research, the question is which architecture performs better for a given dataset. In this paper, we compare the performance of 14 pre-trained ImageNet models on the histopathologic cancer detection dataset, where each model has been configured as a naive model, feature extractor model, or fine-tuned model. Densenet161 has been shown to have high precision whilst Resnet101 has a high recall. A high precision model is suitable to be used when follow-up examination cost is high, whilst low precision but a high recall/sensitivity model can be used when the cost of follow-up examination is low. Results also show that transfer learning helps to converge a model faster.