 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF-RBA: A Federated Learning-based Framework for Risk-based Authentication
Dec 16, 2024

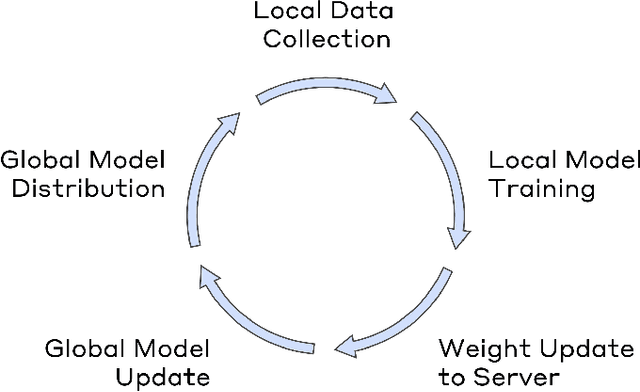

The proliferation of Internet services has led to an increasing need to protect private data. User authentication serves as a crucial mechanism to ensure data security. Although robust authentication forms the cornerstone of remote service security, it can still leave users vulnerable to credential disclosure, device-theft attacks, session hijacking, and inadequate adaptive security measures. Risk-based Authentication (RBA) emerges as a potential solution, offering a multi-level authentication approach that enhances user experience without compromising security. In this paper, we propose a Federated Risk-based Authentication (F-RBA) framework that leverages Federated Learning to ensure privacy-centric training, keeping user data local while distributing learning across devices. Whereas traditional approaches rely on centralized storage, F-RBA introduces a distributed architecture where risk assessment occurs locally on users' devices. The framework's core innovation lies in its similarity-based feature engineering approach, which addresses the heterogeneous data challenges inherent in federated settings, a significant advancement for distributed authentication. By facilitating real-time risk evaluation across devices while maintaining unified user profiles, F-RBA achieves a balance between data protection, security, and scalability. Through its federated approach, F-RBA addresses the cold-start challenge in risk model creation, enabling swift adaptation to new users without compromising security. Empirical evaluation using a real-world multi-user dataset demonstrates the framework's effectiveness, achieving a superior true positive rate for detecting suspicious logins compared to conventional unsupervised anomaly detection models. This research introduces a new paradigm for privacy-focused RBA in distributed digital environments, facilitating advancements in federated security systems.
Lifelong Learning for Fog Load Balancing: A Transfer Learning Approach
Oct 08, 2023

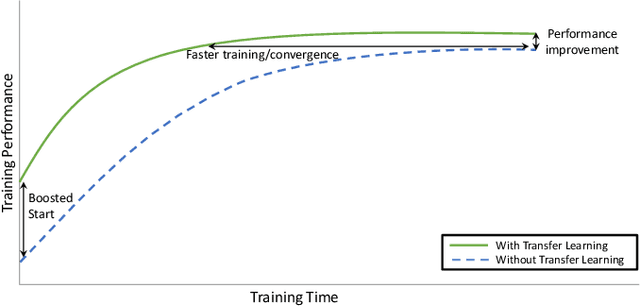
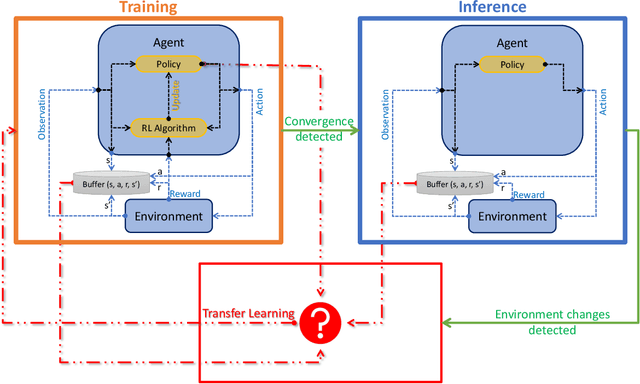
Fog computing emerged as a promising paradigm to address the challenges of processing and managing data generated by the Internet of Things (IoT). Load balancing (LB) plays a crucial role in Fog computing environments to optimize the overall system performance. It requires efficient resource allocation to improve resource utilization, minimize latency, and enhance the quality of service for end-users. In this work, we improve the performance of privacy-aware Reinforcement Learning (RL) agents that optimize the execution delay of IoT applications by minimizing the waiting delay. To maintain privacy, these agents optimize the waiting delay by minimizing the change in the number of queued requests in the whole system, i.e., without explicitly observing the actual number of requests that are queued in each Fog node nor observing the compute resource capabilities of those nodes. Besides improving the performance of these agents, we propose in this paper a lifelong learning framework for these agents, where lightweight inference models are used during deployment to minimize action delay and only retrained in case of significant environmental changes. To improve the performance, minimize the training cost, and adapt the agents to those changes, we explore the application of Transfer Learning (TL). TL transfers the knowledge acquired from a source domain and applies it to a target domain, enabling the reuse of learned policies and experiences. TL can be also used to pre-train the agent in simulation before fine-tuning it in the real environment; this significantly reduces failure probability compared to learning from scratch in the real environment. To our knowledge, there are no existing efforts in the literature that use TL to address lifelong learning for RL-based Fog LB; this is one of the main obstacles in deploying RL LB solutions in Fog systems.
Transaction Confirmation Time Prediction in Ethereum Blockchain Using Machine Learning
Nov 25, 2019



Blockchain offers a decentralized, immutable, transparent system of records. It offers a peer-to-peer network of nodes with no centralised governing entity making it unhackable and therefore, more secure than the traditional paper-based or centralised system of records like banks etc. While there are certain advantages to the paper-based recording approach, it does not work well with digital relationships where the data is in constant flux. Unlike traditional channels, governed by centralized entities, blockchain offers its users a certain level of anonymity by providing capabilities to interact without disclosing their personal identities and allows them to build trust without a third-party governing entity. Due to the aforementioned characteristics of blockchain, more and more users around the globe are inclined towards making a digital transaction via blockchain than via rudimentary channels. Therefore, there is a dire need for us to gain insight on how these transactions are processed by the blockchain and how much time it may take for a peer to confirm a transaction and add it to the blockchain network. This paper presents a novel approach that would allow one to estimate the time, in block time or otherwise, it would take for a mining node to accept and confirm a transaction to a block using machine learning. The paper also aims to compare the predictive accuracy of two machine learning regression models- Random Forest Regressor and Multilayer Perceptron against previously proposed statistical regression model under a set evaluation criterion. The objective is to determine whether machine learning offers a more accurate predictive model than conventional statistical models. The proposed model results in improved accuracy in prediction.