 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem-level Impact of Non-Ideal Program-Time of Charge Trap Flash on Deep Neural Network
Feb 15, 2024



Learning of deep neural networks (DNN) using Resistive Processing Unit (RPU) architecture is energy-efficient as it utilizes dedicated neuromorphic hardware and stochastic computation of weight updates for in-memory computing. Charge Trap Flash (CTF) devices can implement RPU-based weight updates in DNNs. However, prior work has shown that the weight updates (V_T) in CTF-based RPU are impacted by the non-ideal program time of CTF. The non-ideal program time is affected by two factors of CTF. Firstly, the effects of the number of input pulses (N) or pulse width (pw), and secondly, the gap between successive update pulses (t_gap) used for the stochastic computation of weight updates. Therefore, the impact of this non-ideal program time must be studied for neural network training simulations. In this study, Firstly, we propose a pulse-train design compensation technique to reduce the total error caused by non-ideal program time of CTF and stochastic variance of a network. Secondly, we simulate RPU-based DNN with non-ideal program time of CTF on MNIST and Fashion-MNIST datasets. We find that for larger N (~1000), learning performance approaches the ideal (software-level) training level and, therefore, is not much impacted by the choice of t_gap used to implement RPU-based weight updates. However, for lower N (<500), learning performance depends on T_gap of the pulses. Finally, we also performed an ablation study to isolate the causal factor of the improved learning performance. We conclude that the lower noise level in the weight updates is the most likely significant factor to improve the learning performance of DNN. Thus, our study attempts to compensate for the error caused by non-ideal program time and standardize the pulse length (N) and pulse gap (t_gap) specifications for CTF-based RPUs for accurate system-level on-chip training.
Classification of anatomic structures in head and neck by CT-based radiomics
May 17, 2022
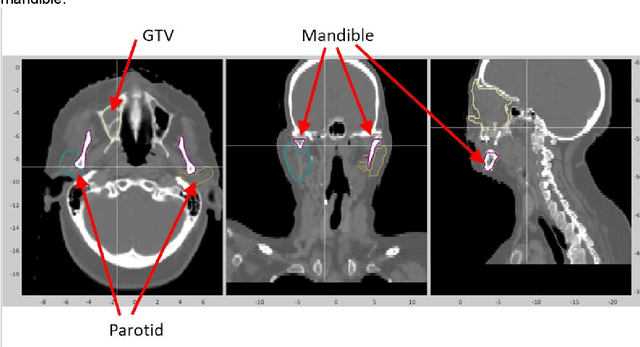
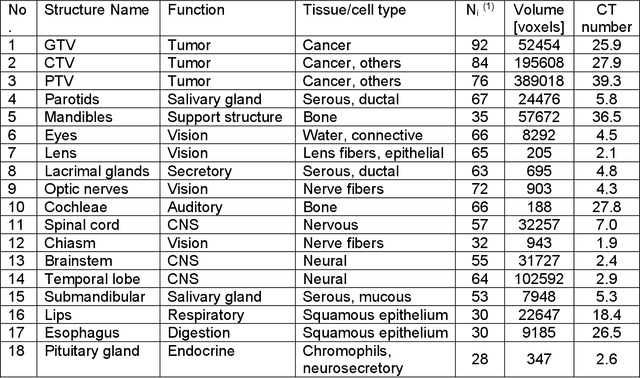

Background and Purpose: Radiomics features are used to identify disease types and predict therapy outcomes. However, how the radiomics features are different among different anatomical structures has never been investigated. Hence, we analyzed the radiomics features of 22 anatomical structures in the head and neck area in CT images. Furthermore, we studied whether CT radiomics can classify anatomical structures of the head and neck using unsupervised machine-learning techniques. Materials and methods: We obtained IMRT/VMAT treatment planning data from 36 patients treated for head and neck cancers in a single institution. There were 1357 contours of more than 22 anatomical structures drawn on planning CTs. We calculated 174 radiomics features using the SIBEX program. First, we tested whether the radiomics features of anatomical structures were unique enough to classify all contours into 22 groups. We then developed a two-stage clustering technique to classify 22 anatomic structures into sub-groups with similar physiological or biological characteristics. Results: The heatmap of 174 radiomics features of 22 anatomical structures showed a distinct difference among tumors and other healthy structures. Radiomics features have allowed us to identify the eyes, lens, submandibular, pituitary glands, and thyroids with over 90% accuracy. The two-stage clustering of 22 structures resulted in six subgroups, which shared common characteristics such as fatty and bony tissues. Conclusions: We have shown that anatomical structures in head and neck tumors have distinguishable radiomics features. We could observe similarities of features among subgroups of the structures. The results suggest that CT radiomics can help distinguish the biological characteristics of head and neck lesions.
Semi-supervised acoustic modelling for five-lingual code-switched ASR using automatically-segmented soap opera speech
Apr 08, 2020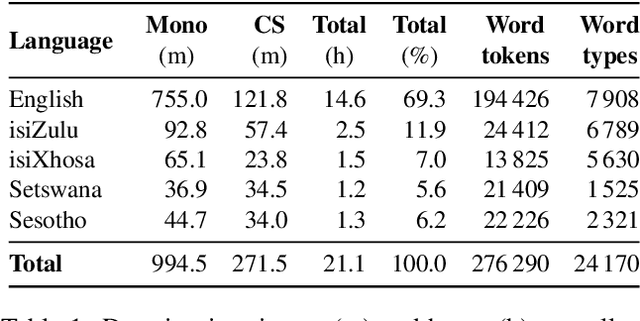
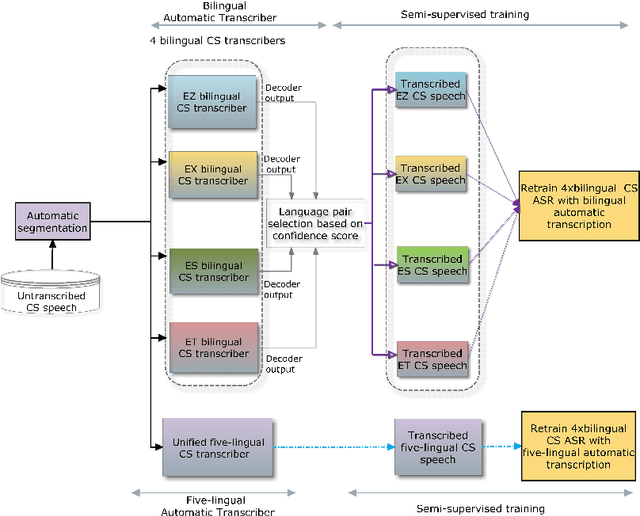

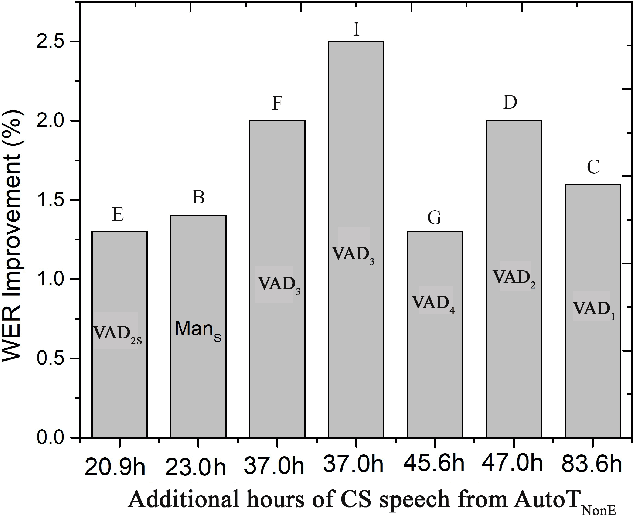
This paper considers the impact of automatic segmentation on the fully-automatic, semi-supervised training of automatic speech recognition (ASR) systems for five-lingual code-switched (CS) speech. Four automatic segmentation techniques were evaluated in terms of the recognition performance of an ASR system trained on the resulting segments in a semi-supervised manner. The system's output was compared with the recognition rates achieved by a semi-supervised system trained on manually assigned segments. Three of the automatic techniques use a newly proposed convolutional neural network (CNN) model for framewise classification, and include a novel form of HMM smoothing of the CNN outputs. Automatic segmentation was applied in combination with automatic speaker diarization. The best-performing segmentation technique was also tested without speaker diarization. An evaluation based on 248 unsegmented soap opera episodes indicated that voice activity detection (VAD) based on a CNN followed by Gaussian mixture modelhidden Markov model smoothing (CNN-GMM-HMM) yields the best ASR performance. The semi-supervised system trained with the resulting segments achieved an overall WER improvement of 1.1% absolute over the system trained with manually created segments. Furthermore, we found that system performance improved even further when the automatic segmentation was used in conjunction with speaker diarization.
Semi-supervised acoustic and language model training for English-isiZulu code-switched speech recognition
Apr 05, 2020
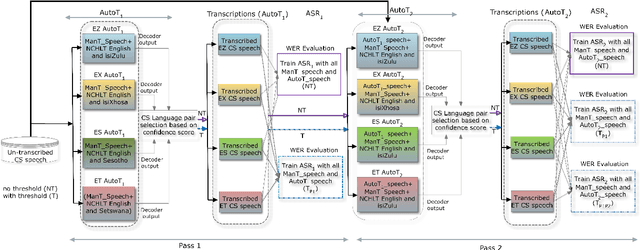
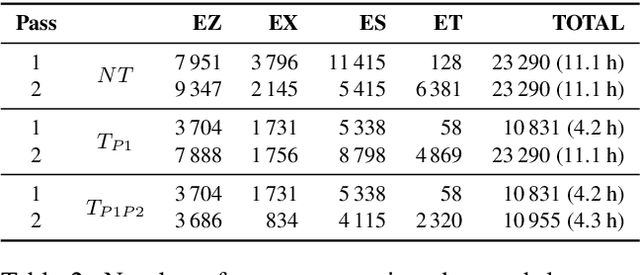
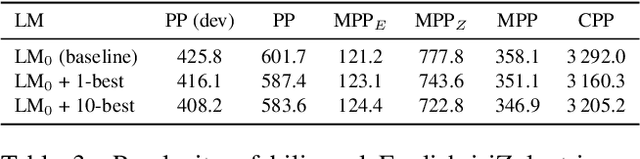
We present an analysis of semi-supervised acoustic and language model training for English-isiZulu code-switched ASR using soap opera speech. Approximately 11 hours of untranscribed multilingual speech was transcribed automatically using four bilingual code-switching transcription systems operating in English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho. These transcriptions were incorporated into the acoustic and language model training sets. Results showed that the TDNN-F acoustic models benefit from the additional semi-supervised data and that even better performance could be achieved by including additional CNN layers. Using these CNN-TDNN-F acoustic models, a first iteration of semi-supervised training achieved an absolute mixed-language WER reduction of 3.4%, and a further 2.2% after a second iteration. Although the languages in the untranscribed data were unknown, the best results were obtained when all automatically transcribed data was used for training and not just the utterances classified as English-isiZulu. Despite reducing perplexity, the semi-supervised language model was not able to improve the ASR performance.