 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation Schemes for Building ASR in Low-resource Languages
Sep 16, 2021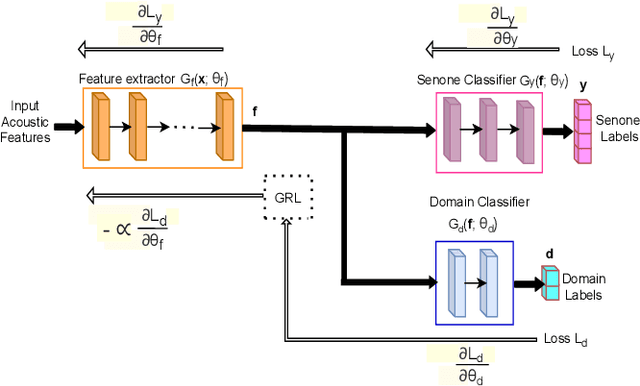
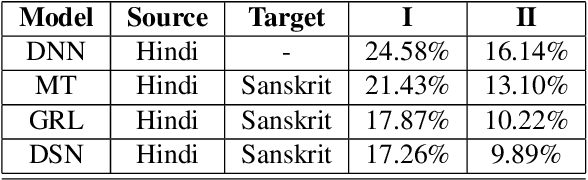
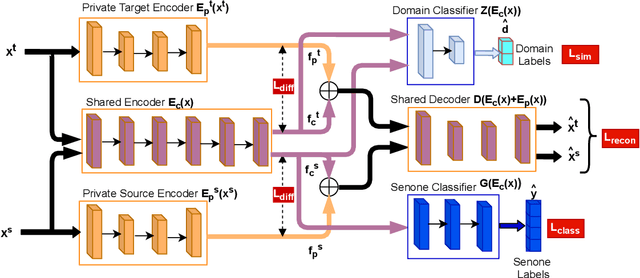
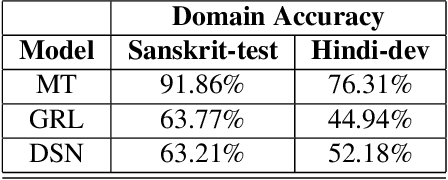
Building an automatic speech recognition (ASR) system from scratch requires a large amount of annotated speech data, which is difficult to collect in many languages. However, there are cases where the low-resource language shares a common acoustic space with a high-resource language having enough annotated data to build an ASR. In such cases, we show that the domain-independent acoustic models learned from the high-resource language through unsupervised domain adaptation (UDA) schemes can enhance the performance of the ASR in the low-resource language. We use the specific example of Hindi in the source domain and Sanskrit in the target domain. We explore two architectures: i) domain adversarial training using gradient reversal layer (GRL) and ii) domain separation networks (DSN). The GRL and DSN architectures give absolute improvements of 6.71% and 7.32%, respectively, in word error rate over the baseline deep neural network model when trained on just 5.5 hours of data in the target domain. We also show that choosing a proper language (Telugu) in the source domain can bring further improvement. The results suggest that UDA schemes can be helpful in the development of ASR systems for low-resource languages, mitigating the hassle of collecting large amounts of annotated speech data.
Improving Facial Emotion Recognition Systems Using Gradient and Laplacian Images
Feb 12, 2019

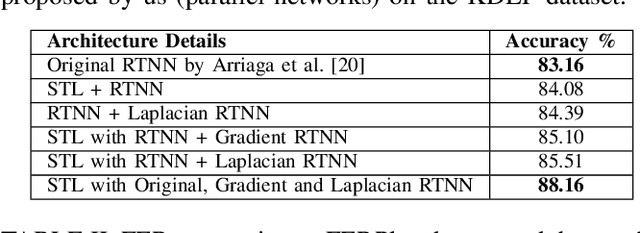
In this work, we have proposed several enhancements to improve the performance of any facial emotion recognition (FER) system. We believe that the changes in the positions of the fiducial points and the intensities capture the crucial information regarding the emotion of a face image. We propose the use of the gradient and the Laplacian of the input image together with the original input into a convolutional neural network (CNN). These modifications help the network learn additional information from the gradient and Laplacian of the images. However, the plain CNN is not able to extract this information from the raw images. We have performed a number of experiments on two well known datasets KDEF and FERplus. Our approach enhances the already high performance of state-of-the-art FER systems by 3 to 5%.
Binary Document Image Super Resolution for Improved Readability and OCR Performance
Dec 06, 2018

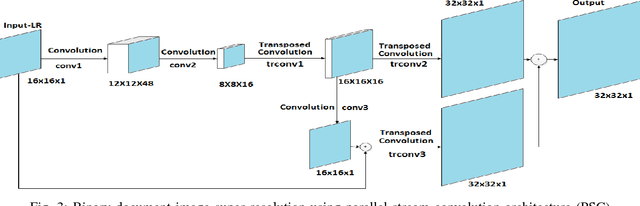

There is a need for information retrieval from large collections of low-resolution (LR) binary document images, which can be found in digital libraries across the world, where the high-resolution (HR) counterpart is not available. This gives rise to the problem of binary document image super-resolution (BDISR). The objective of this paper is to address the interesting and challenging problem of super resolution of binary Tamil document images for improved readability and better optical character recognition (OCR). We propose multiple deep neural network architectures to address this problem and analyze their performance. The proposed models are all single image super-resolution techniques, which learn a generalized spatial correspondence between the LR and HR binary document images. We employ convolutional layers for feature extraction followed by transposed convolution and sub-pixel convolution layers for upscaling the features. Since the outputs of the neural networks are gray scale, we utilize the advantage of power law transformation as a post-processing technique to improve the character level pixel connectivity. The performance of our models is evaluated by comparing the OCR accuracies and the mean opinion scores given by human evaluators on LR images and the corresponding model-generated HR images.
MSCE: An edge preserving robust loss function for improving super-resolution algorithms
Aug 25, 2018
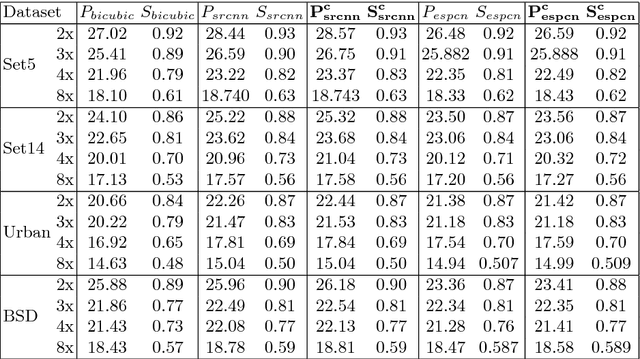

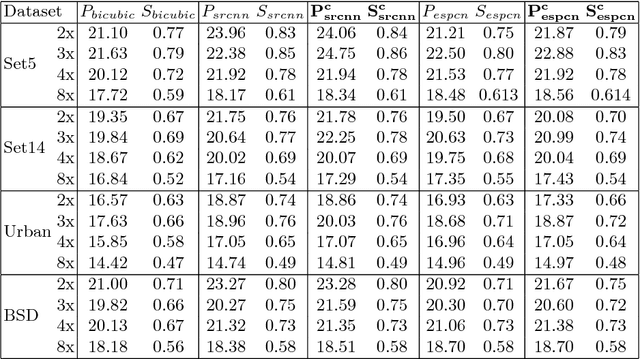
With the recent advancement in the deep learning technologies such as CNNs and GANs, there is significant improvement in the quality of the images reconstructed by deep learning based super-resolution (SR) techniques. In this work, we propose a robust loss function based on the preservation of edges obtained by the Canny operator. This loss function, when combined with the existing loss function such as mean square error (MSE), gives better SR reconstruction measured in terms of PSNR and SSIM. Our proposed loss function guarantees improved performance on any existing algorithm using MSE loss function, without any increase in the computational complexity during testing.
Computationally Efficient Approaches for Image Style Transfer
Jul 16, 2018
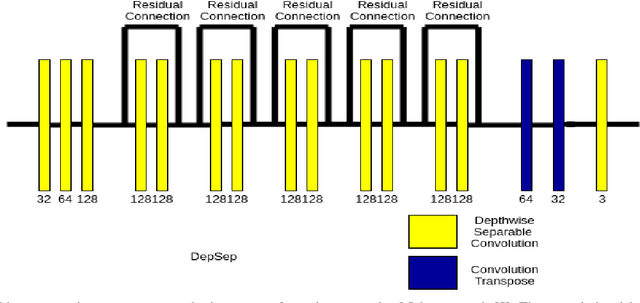


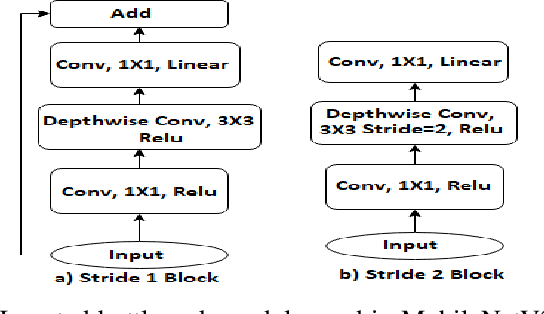
In this work, we have investigated various style transfer approaches and (i) examined how the stylized reconstruction changes with the change of loss function and (ii) provided a computationally efficient solution for the same. We have used elegant techniques like depth-wise separable convolution in place of convolution and nearest neighbor interpolation in place of transposed convolution. Further, we have also added multiple interpolations in place of transposed convolution. The results obtained are perceptually similar in quality, while being computationally very efficient. The decrease in the computational complexity of our architecture is validated by the decrease in the testing time by 26.1%, 39.1%, and 57.1%, respectively.
A hybrid approach of interpolations and CNN to obtain super-resolution
May 23, 2018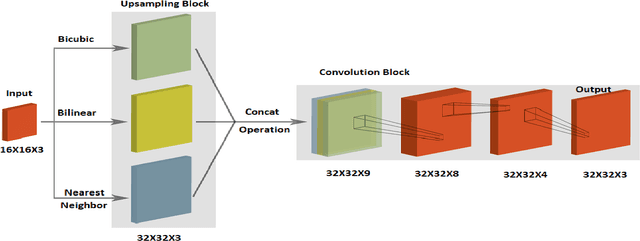

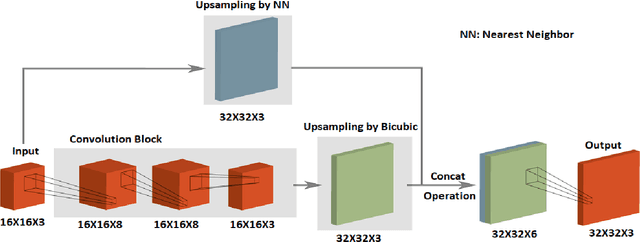

We propose a novel architecture that learns an end-to-end mapping function to improve the spatial resolution of the input natural images. The model is unique in forming a nonlinear combination of three traditional interpolation techniques using the convolutional neural network. Another proposed architecture uses a skip connection with nearest neighbor interpolation, achieving almost similar results. The architectures have been carefully designed to ensure that the reconstructed images lie precisely in the manifold of high-resolution images, thereby preserving the high-frequency components with fine details. We have compared with the state of the art and recent deep learning based natural image super-resolution techniques and found that our methods are able to preserve the sharp details in the image, while also obtaining comparable or better PSNR than them. Since our methods use only traditional interpolations and a shallow CNN with less number of smaller filters, the computational cost is kept low. We have reported the results of two proposed architectures on five standard datasets, for an upscale factor of 2. Our methods generalize well in most cases, which is evident from the better results obtained with increasingly complex datasets. For 4-times upscaling, we have designed similar architectures for comparing with other methods.
Segmentation of Liver Lesions with Reduced Complexity Deep Models
May 23, 2018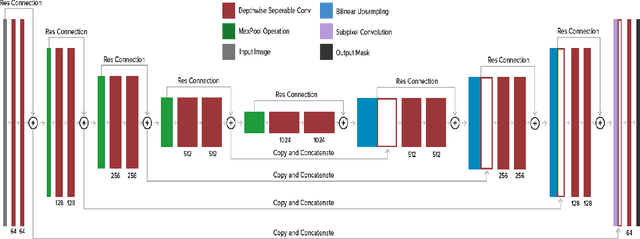
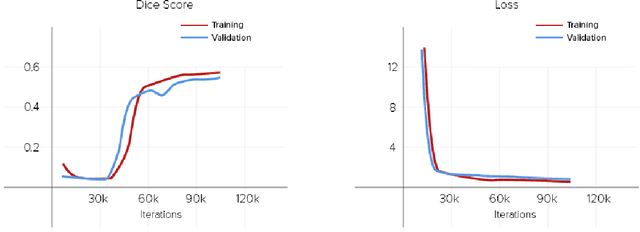
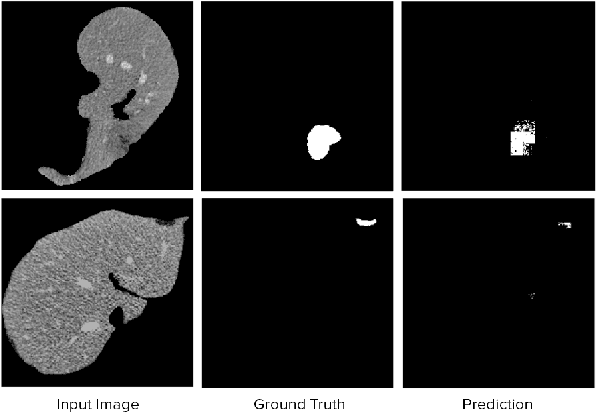
We propose a computationally efficient architecture that learns to segment lesions from CT images of the liver. The proposed architecture uses bilinear interpolation with sub-pixel convolution at the last layer to upscale the course feature in bottle neck architecture. Since bilinear interpolation and sub-pixel convolution do not have any learnable parameter, our overall model is faster and occupies less memory footprint than the traditional U-net. We evaluate our proposed architecture on the highly competitive dataset of 2017 Liver Tumor Segmentation (LiTS) Challenge. Our method achieves competitive results while reducing the number of learnable parameters roughly by a factor of 13.8 compared to the original UNet model.
Language Independent Single Document Image Super-Resolution using CNN for improved recognition
Jan 30, 2017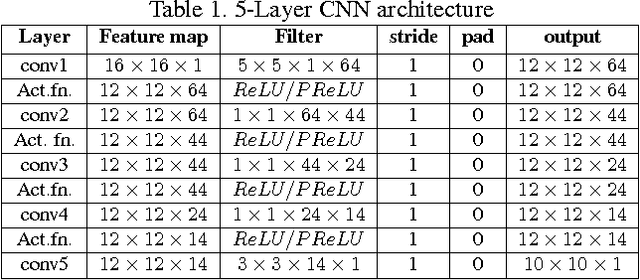
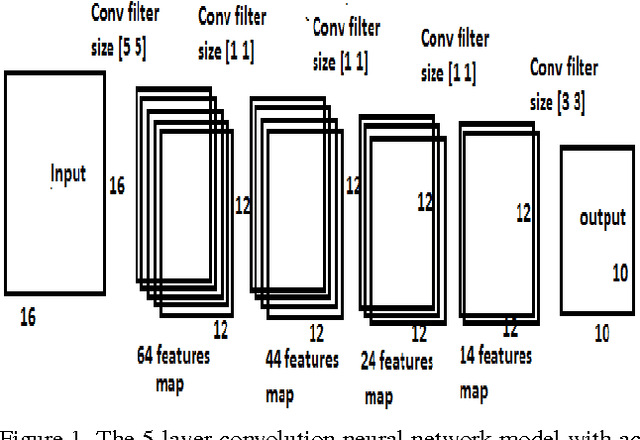

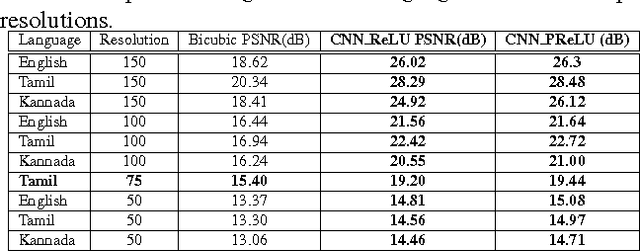
Recognition of document images have important applications in restoring old and classical texts. The problem involves quality improvement before passing it to a properly trained OCR to get accurate recognition of the text. The image enhancement and quality improvement constitute important steps as subsequent recognition depends upon the quality of the input image. There are scenarios when high resolution images are not available and our experiments show that the OCR accuracy reduces significantly with decrease in the spatial resolution of document images. Thus the only option is to improve the resolution of such document images. The goal is to construct a high resolution image, given a single low resolution binary image, which constitutes the problem of single image super-resolution. Most of the previous work in super-resolution deal with natural images which have more information-content than the document images. Here, we use Convolution Neural Network to learn the mapping between low and the corresponding high resolution images. We experiment with different number of layers, parameter settings and non-linear functions to build a fast end-to-end framework for document image super-resolution. Our proposed model shows a very good PSNR improvement of about 4 dB on 75 dpi Tamil images, resulting in a 3 % improvement of word level accuracy by the OCR. It takes less time than the recent sparse based natural image super-resolution technique, making it useful for real-time document recognition applications.
Quadratically constrained quadratic programming for classification using particle swarms and applications
Jul 23, 2014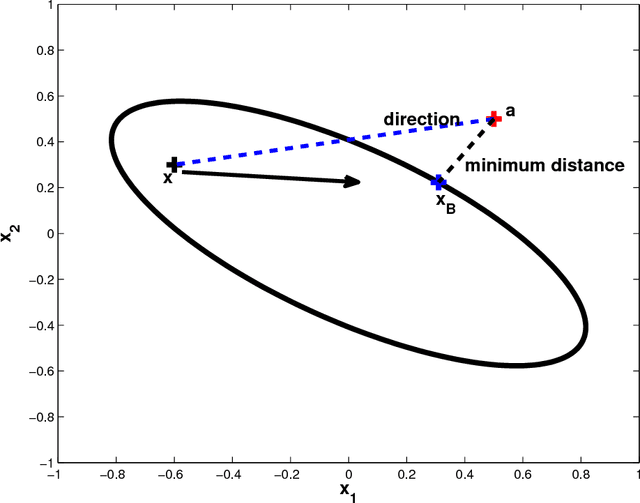

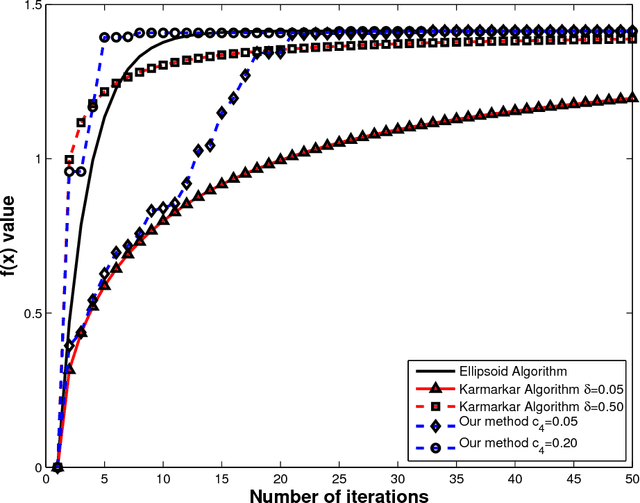

Particle swarm optimization is used in several combinatorial optimization problems. In this work, particle swarms are used to solve quadratic programming problems with quadratic constraints. The approach of particle swarms is an example for interior point methods in optimization as an iterative technique. This approach is novel and deals with classification problems without the use of a traditional classifier. Our method determines the optimal hyperplane or classification boundary for a data set. In a binary classification problem, we constrain each class as a cluster, which is enclosed by an ellipsoid. The estimation of the optimal hyperplane between the two clusters is posed as a quadratically constrained quadratic problem. The optimization problem is solved in distributed format using modified particle swarms. Our method has the advantage of using the direction towards optimal solution rather than searching the entire feasible region. Our results on the Iris, Pima, Wine, and Thyroid datasets show that the proposed method works better than a neural network and the performance is close to that of SVM.
Benchmarking recognition results on word image datasets
Aug 30, 2012


We have benchmarked the maximum obtainable recognition accuracy on various word image datasets using manual segmentation and a currently available commercial OCR. We have developed a Matlab program, with graphical user interface, for semi-automated pixel level segmentation of word images. We discuss the advantages of pixel level annotation. We have covered five databases adding up to over 3600 word images. These word images have been cropped from camera captured scene, born-digital and street view images. We recognize the segmented word image using the trial version of Nuance Omnipage OCR. We also discuss, how the degradations introduced during acquisition or inaccuracies introduced during creation of word images affect the recognition of the word present in the image. Word images for different kinds of degradations and correction for slant and curvy nature of words are also discussed. The word recognition rates obtained on ICDAR 2003, Sign evaluation, Street view, Born-digital and ICDAR 2011 datasets are 83.9%, 89.3%, 79.6%, 88.5% and 86.7% respectively.