 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinarized Neural Machine Translation
Feb 09, 2023

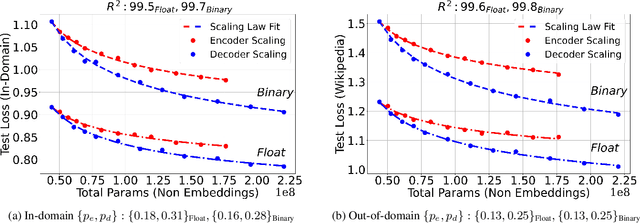

The rapid scaling of language models is motivating research using low-bitwidth quantization. In this work, we propose a novel binarization technique for Transformers applied to machine translation (BMT), the first of its kind. We identify and address the problem of inflated dot-product variance when using one-bit weights and activations. Specifically, BMT leverages additional LayerNorms and residual connections to improve binarization quality. Experiments on the WMT dataset show that a one-bit weight-only Transformer can achieve the same quality as a float one, while being 16x smaller in size. One-bit activations incur varying degrees of quality drop, but mitigated by the proposed architectural changes. We further conduct a scaling law study using production-scale translation datasets, which shows that one-bit weight Transformers scale and generalize well in both in-domain and out-of-domain settings. Implementation in JAX/Flax will be open sourced.