Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Voice Conditioning for Denoising Diffusion TTS Models
Paper and Code
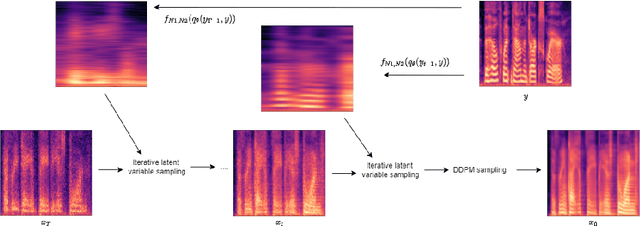
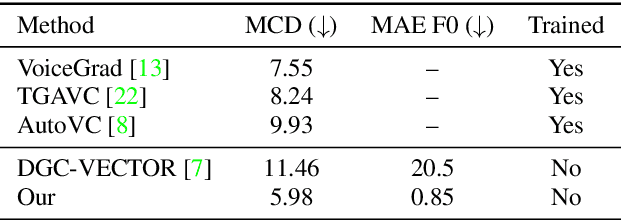
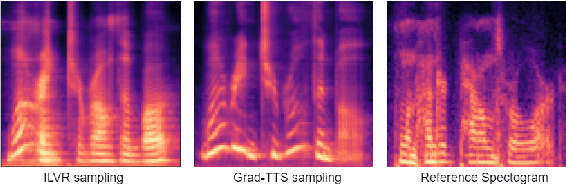
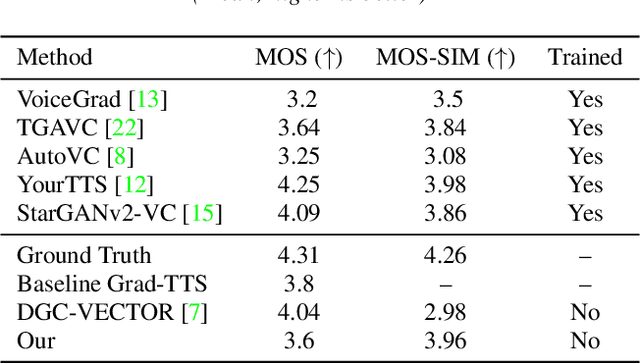
We present a novel way of conditioning a pretrained denoising diffusion speech model to produce speech in the voice of a novel person unseen during training. The method requires a short (~3 seconds) sample from the target person, and generation is steered at inference time, without any training steps. At the heart of the method lies a sampling process that combines the estimation of the denoising model with a low-pass version of the new speaker's sample. The objective and subjective evaluations show that our sampling method can generate a voice similar to that of the target speaker in terms of frequency, with an accuracy comparable to state-of-the-art methods, and without training.
View paper on