 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Learning from scratch (ZFS): leveraging local compositional representations
Paper and Code
Oct 22, 2020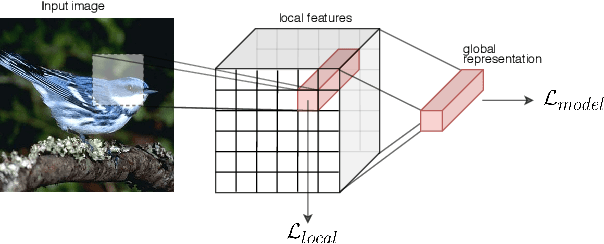
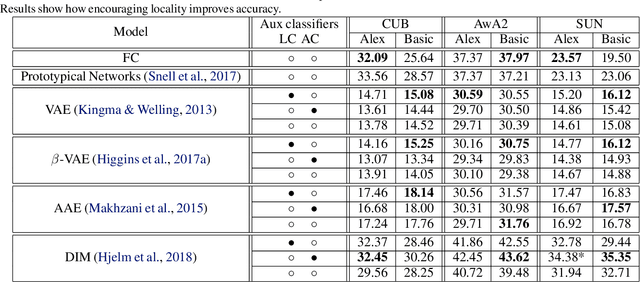
Zero-shot classification is a generalization task where no instance from the target classes is seen during training. To allow for test-time transfer, each class is annotated with semantic information, commonly in the form of attributes or text descriptions. While classical zero-shot learning does not explicitly forbid using information from other datasets, the approaches that achieve the best absolute performance on image benchmarks rely on features extracted from encoders pretrained on Imagenet. This approach relies on hyper-optimized Imagenet-relevant parameters from the supervised classification setting, entangling important questions about the suitability of those parameters and how they were learned with more fundamental questions about representation learning and generalization. To remove these distractors, we propose a more challenging setting: Zero-Shot Learning from scratch (ZFS), which explicitly forbids the use of encoders fine-tuned on other datasets. Our analysis on this setting highlights the importance of local information, and compositional representations.