 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Joint Modeling of Multiple Spoken-Text-Style Conversion Tasks using Switching Tokens
Paper and Code
Jun 23, 2021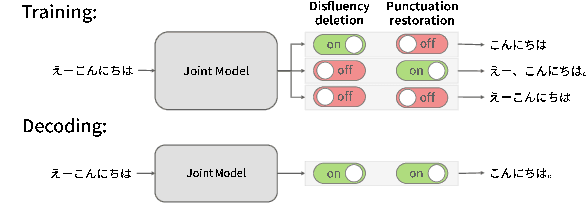
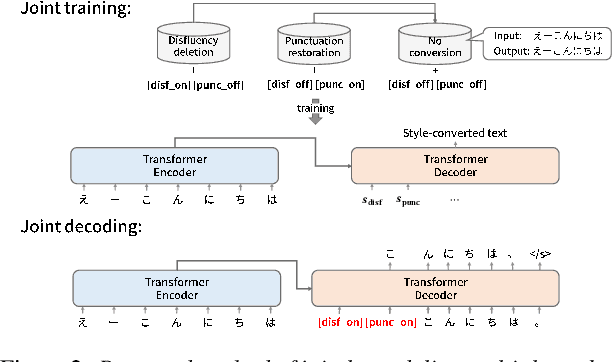
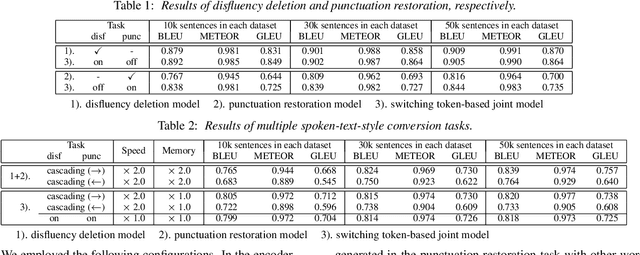
In this paper, we propose a novel spoken-text-style conversion method that can simultaneously execute multiple style conversion modules such as punctuation restoration and disfluency deletion without preparing matched datasets. In practice, transcriptions generated by automatic speech recognition systems are not highly readable because they often include many disfluencies and do not include punctuation marks. To improve their readability, multiple spoken-text-style conversion modules that individually model a single conversion task are cascaded because matched datasets that simultaneously handle multiple conversion tasks are often unavailable. However, the cascading is unstable against the order of tasks because of the chain of conversion errors. Besides, the computation cost of the cascading must be higher than the single conversion. To execute multiple conversion tasks simultaneously without preparing matched datasets, our key idea is to distinguish individual conversion tasks using the on-off switch. In our proposed zero-shot joint modeling, we switch the individual tasks using multiple switching tokens, enabling us to utilize a zero-shot learning approach to executing simultaneous conversions. Our experiments on joint modeling of disfluency deletion and punctuation restoration demonstrate the effectiveness of our method.