Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Conversational Summarization Evaluations with small Large Language Models
Paper and Code
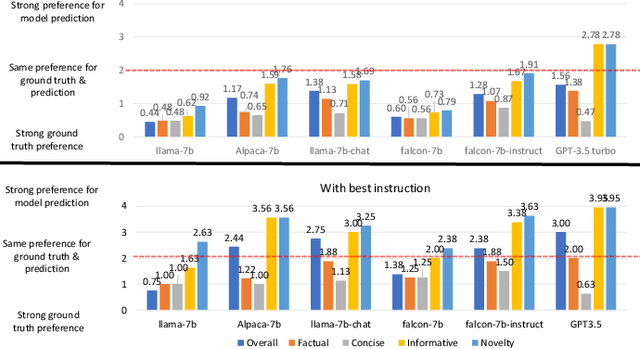
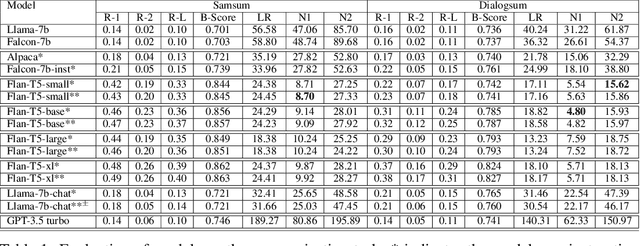
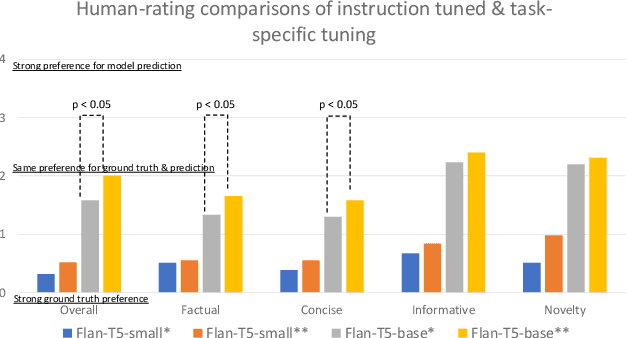
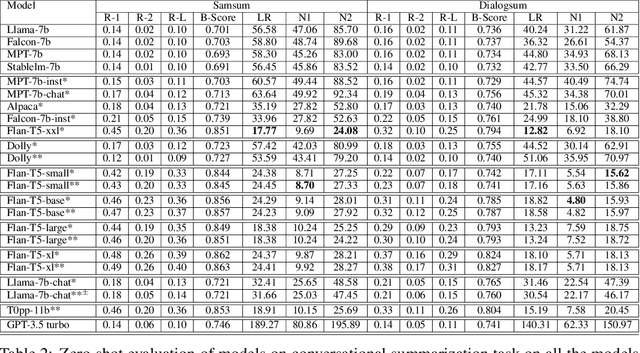
Large Language Models (LLMs) exhibit powerful summarization abilities. However, their capabilities on conversational summarization remains under explored. In this work we evaluate LLMs (approx. 10 billion parameters) on conversational summarization and showcase their performance on various prompts. We show that the summaries generated by models depend on the instructions and the performance of LLMs vary with different instructions sometimes resulting steep drop in ROUGE scores if prompts are not selected carefully. We also evaluate the models with human evaluations and discuss the limitations of the models on conversational summarization
* Accepted at RoF0Mo workshop at Neurips 2023
View paper on