 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-bias autoencoders and the benefits of co-adapting features
Paper and Code
Apr 08, 2015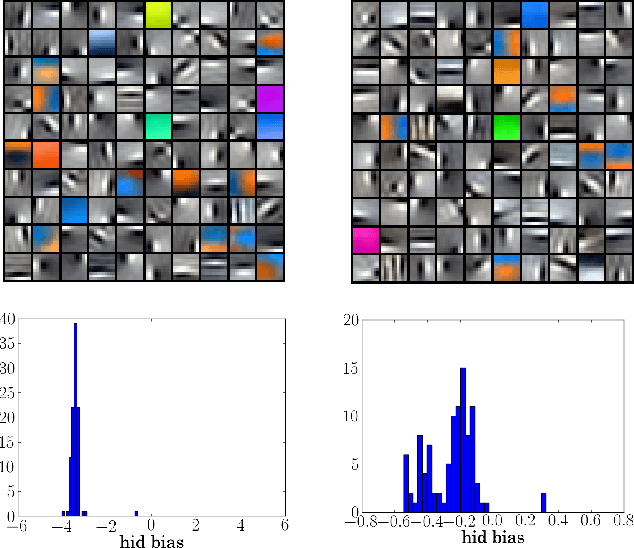

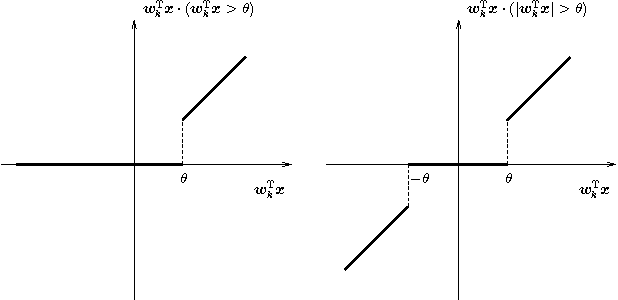
Regularized training of an autoencoder typically results in hidden unit biases that take on large negative values. We show that negative biases are a natural result of using a hidden layer whose responsibility is to both represent the input data and act as a selection mechanism that ensures sparsity of the representation. We then show that negative biases impede the learning of data distributions whose intrinsic dimensionality is high. We also propose a new activation function that decouples the two roles of the hidden layer and that allows us to learn representations on data with very high intrinsic dimensionality, where standard autoencoders typically fail. Since the decoupled activation function acts like an implicit regularizer, the model can be trained by minimizing the reconstruction error of training data, without requiring any additional regularization.