 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeY-NQ: English-Yorùbá Evaluation dataset for Open-Book Reading Comprehension and Text Generation
Paper and Code
Dec 11, 2024
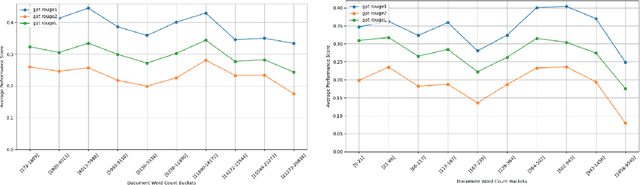
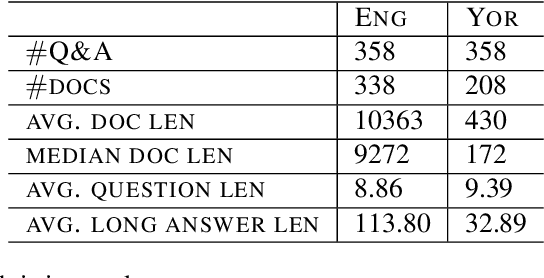
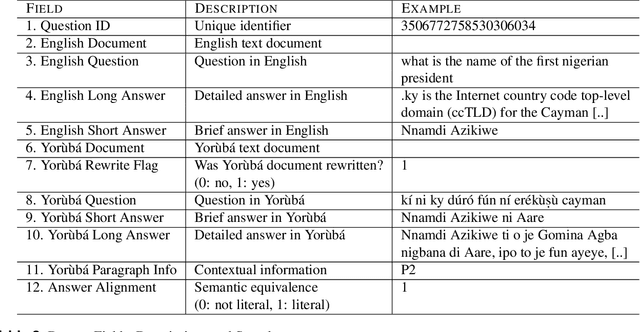
The purpose of this work is to share an English-Yor\`ub\'a evaluation dataset for open-book reading comprehension and text generation to assess the performance of models both in a high- and a low- resource language. The dataset contains 358 questions and answers on 338 English documents and 208 Yor\`ub\'a documents. The average document length is ~ 10k words for English and 430 words for Yor\`ub\'a. Experiments show a consistent disparity in performance between the two languages, with Yor\`ub\'a falling behind English for automatic metrics even if documents are much shorter for this language. For a small set of documents with comparable length, performance of Yor\`ub\'a drops by x2.5 times. When analyzing performance by length, we observe that Yor\`ub\'a decreases performance dramatically for documents that reach 1500 words while English performance is barely affected at that length. Our dataset opens the door to showcasing if English LLM reading comprehension capabilities extend to Yor\`ub\'a, which for the evaluated LLMs is not the case.