 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-NeRF: Explicit Neural Radiance Field for Multi-Scene 360$^{\circ} $ Insufficient RGB-D Views
Paper and Code

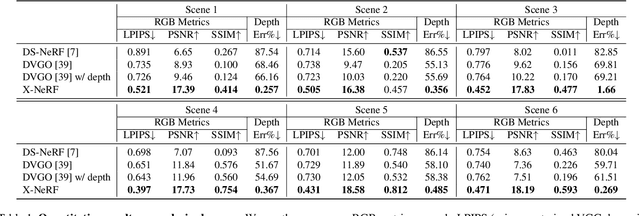


Neural Radiance Fields (NeRFs), despite their outstanding performance on novel view synthesis, often need dense input views. Many papers train one model for each scene respectively and few of them explore incorporating multi-modal data into this problem. In this paper, we focus on a rarely discussed but important setting: can we train one model that can represent multiple scenes, with 360$^\circ $ insufficient views and RGB-D images? We refer insufficient views to few extremely sparse and almost non-overlapping views. To deal with it, X-NeRF, a fully explicit approach which learns a general scene completion process instead of a coordinate-based mapping, is proposed. Given a few insufficient RGB-D input views, X-NeRF first transforms them to a sparse point cloud tensor and then applies a 3D sparse generative Convolutional Neural Network (CNN) to complete it to an explicit radiance field whose volumetric rendering can be conducted fast without running networks during inference. To avoid overfitting, besides common rendering loss, we apply perceptual loss as well as view augmentation through random rotation on point clouds. The proposed methodology significantly out-performs previous implicit methods in our setting, indicating the great potential of proposed problem and approach. Codes and data are available at https://github.com/HaoyiZhu/XNeRF.