 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWSRNet: Joint Spotting and Recognition of Handwritten Words
Paper and Code
Aug 17, 2020
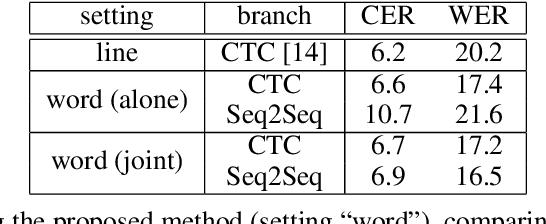
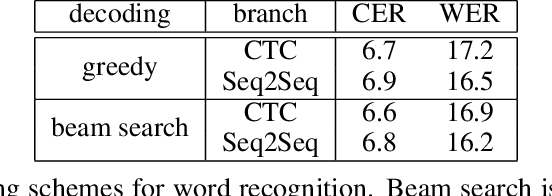

In this work, we present a unified model that can handle both Keyword Spotting and Word Recognition with the same network architecture. The proposed network is comprised of a non-recurrent CTC branch and a Seq2Seq branch that is further augmented with an Autoencoding module. The related joint loss leads to a boost in recognition performance, while the Seq2Seq branch is used to create efficient word representations. We show how to further process these representations with binarization and a retraining scheme to provide compact and highly efficient descriptors, suitable for keyword spotting. Numerical results validate the usefulness of the proposed architecture, as our method outperforms the previous state-of-the-art in keyword spotting, and provides results in the ballpark of the leading methods for word recognition.