 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords of Wisdom: Representational Harms in Learning From AI Communication
Paper and Code
Nov 16, 2021
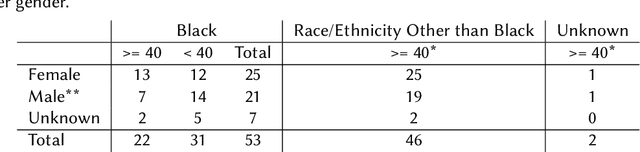
Many educational technologies use artificial intelligence (AI) that presents generated or produced language to the learner. We contend that all language, including all AI communication, encodes information about the identity of the human or humans who contributed to crafting the language. With AI communication, however, the user may index identity information that does not match the source. This can lead to representational harms if language associated with one cultural group is presented as "standard" or "neutral", if the language advantages one group over another, or if the language reinforces negative stereotypes. In this work, we discuss a case study using a Visual Question Generation (VQG) task involving gathering crowdsourced data from targeted demographic groups. Generated questions will be presented to human evaluators to understand how they index the identity behind the language, whether and how they perceive any representational harms, and how they would ideally address any such harms caused by AI communication. We reflect on the educational applications of this work as well as the implications for equality, diversity, and inclusion (EDI).