 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWolf2Pack: The AutoFusion Framework for Dynamic Parameter Fusion
Paper and Code
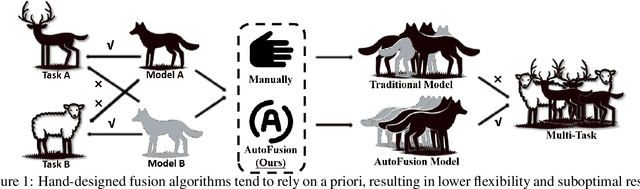
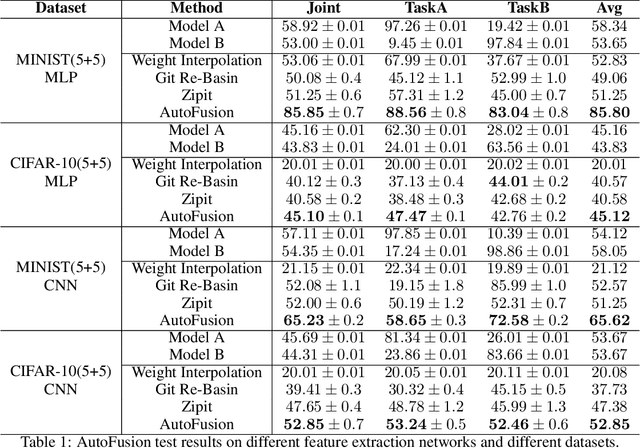
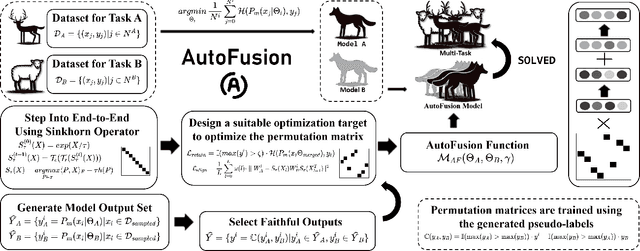
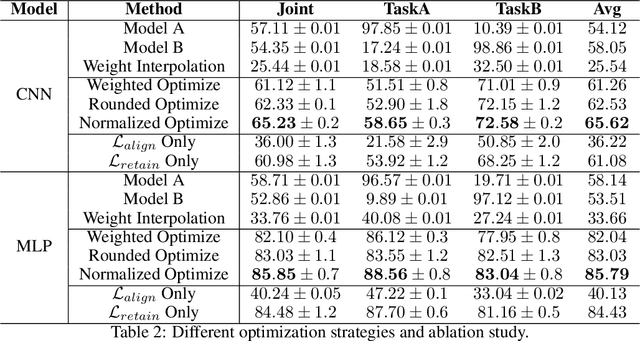
In the rapidly evolving field of deep learning, specialized models have driven significant advancements in tasks such as computer vision and natural language processing. However, this specialization leads to a fragmented ecosystem where models lack the adaptability for broader applications. To overcome this, we introduce AutoFusion, an innovative framework that fuses distinct model parameters(with the same architecture) for multi-task learning without pre-trained checkpoints. Using an unsupervised, end-to-end approach, AutoFusion dynamically permutes model parameters at each layer, optimizing the combination through a loss-minimization process that does not require labeled data. We validate AutoFusion's effectiveness through experiments on commonly used benchmark datasets, demonstrating superior performance over established methods like Weight Interpolation, Git Re-Basin, and ZipIt. Our framework offers a scalable and flexible solution for model integration, positioning it as a powerful tool for future research and practical applications.