 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWNARS: WFST based Non-autoregressive Streaming End-to-End Speech Recognition
Paper and Code
Apr 21, 2021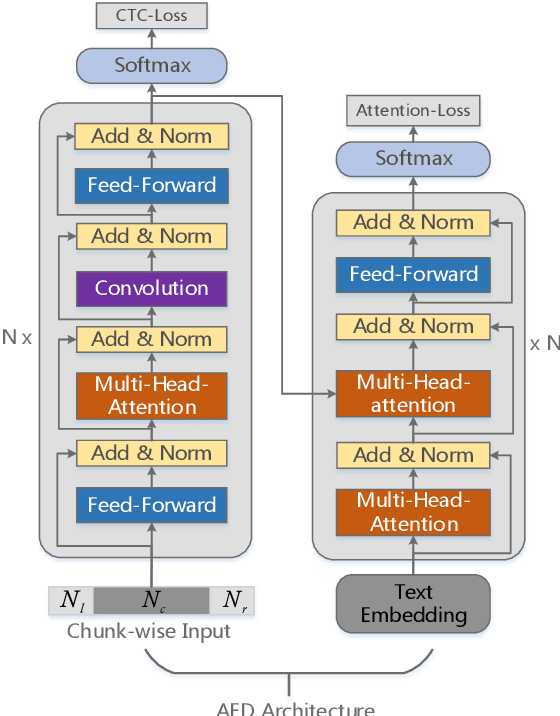


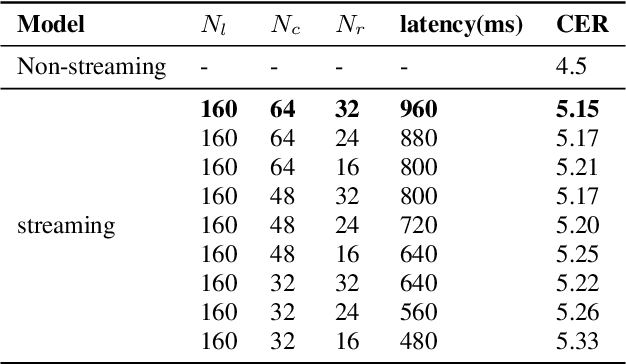
Recently, attention-based encoder-decoder (AED) end-to-end (E2E) models have drawn more and more attention in the field of automatic speech recognition (ASR). AED models, however, still have drawbacks when deploying in commercial applications. Autoregressive beam search decoding makes it inefficient for high-concurrency applications. It is also inconvenient to integrate external word-level language models. The most important thing is that AED models are difficult for streaming recognition due to global attention mechanism. In this paper, we propose a novel framework, namely WNARS, using hybrid CTC-attention AED models and weighted finite-state transducers (WFST) to solve these problems together. We switch from autoregressive beam search to CTC branch decoding, which performs first-pass decoding with WFST in chunk-wise streaming way. The decoder branch then performs second-pass rescoring on the generated hypotheses non-autoregressively. On the AISHELL-1 task, our WNARS achieves a character error rate of 5.22% with 640ms latency, to the best of our knowledge, which is the state-of-the-art performance for online ASR. Further experiments on our 10,000-hour Mandarin task show the proposed method achieves more than 20% improvements with 50% latency compared to a strong TDNN-BLSTM lattice-free MMI baseline.