 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWLV-RIT at SemEval-2021 Task 5: A Neural Transformer Framework for Detecting Toxic Spans
Paper and Code

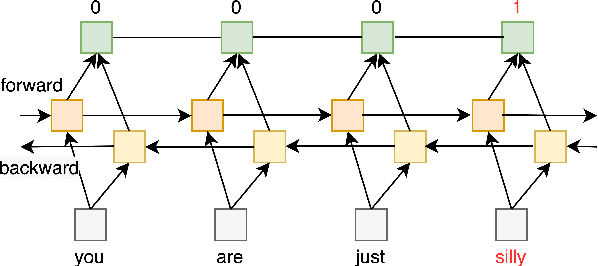
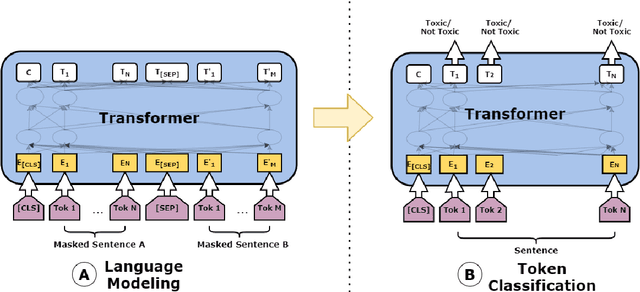
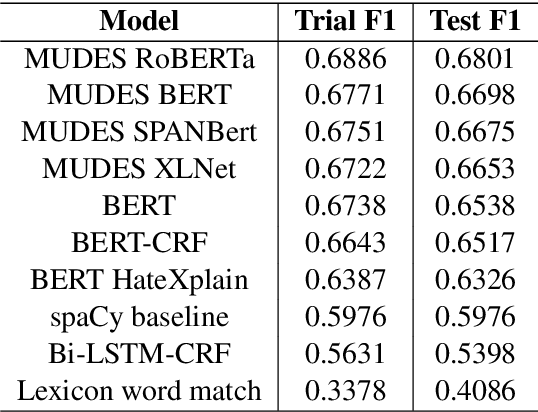
In recent years, the widespread use of social media has led to an increase in the generation of toxic and offensive content on online platforms. In response, social media platforms have worked on developing automatic detection methods and employing human moderators to cope with this deluge of offensive content. While various state-of-the-art statistical models have been applied to detect toxic posts, there are only a few studies that focus on detecting the words or expressions that make a post offensive. This motivates the organization of the SemEval-2021 Task 5: Toxic Spans Detection competition, which has provided participants with a dataset containing toxic spans annotation in English posts. In this paper, we present the WLV-RIT entry for the SemEval-2021 Task 5. Our best performing neural transformer model achieves an $0.68$ F1-Score. Furthermore, we develop an open-source framework for multilingual detection of offensive spans, i.e., MUDES, based on neural transformers that detect toxic spans in texts.