 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWireless Quantized Federated Learning: A Joint Computation and Communication Design
Paper and Code
Mar 11, 2022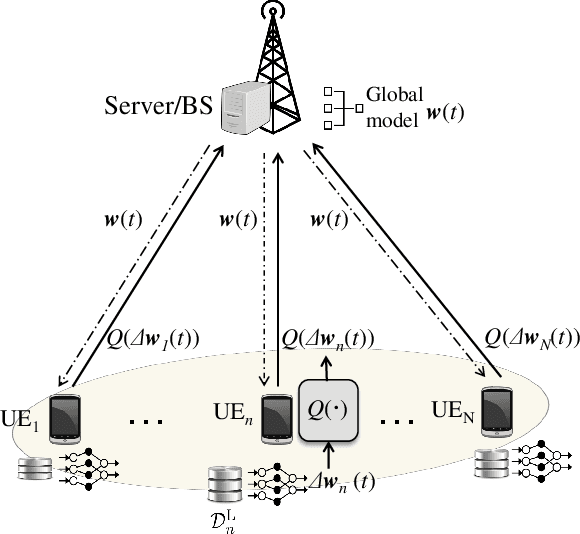


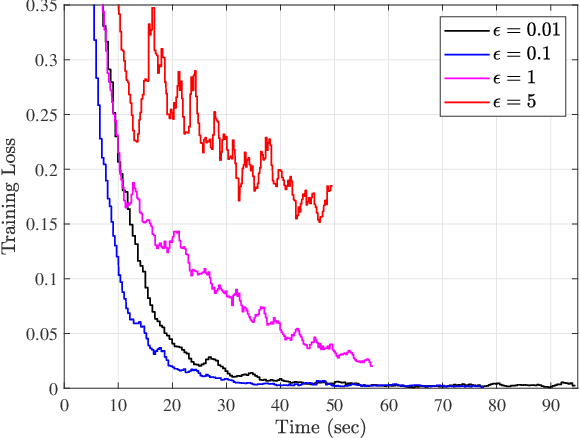
Recently, federated learning (FL) has sparked widespread attention as a promising decentralized machine learning approach which provides privacy and low delay. However, communication bottleneck still constitutes an issue, that needs to be resolved for an efficient deployment of FL over wireless networks. In this paper, we aim to minimize the total convergence time of FL, by quantizing the local model parameters prior to uplink transmission. More specifically, the convergence analysis of the FL algorithm with stochastic quantization is firstly presented, which reveals the impact of the quantization error on the convergence rate. Following that, we jointly optimize the computing, communication resources and number of quantization bits, in order to guarantee minimized convergence time across all global rounds, subject to energy and quantization error requirements, which stem from the convergence analysis. The impact of the quantization error on the convergence time is evaluated and the trade-off among model accuracy and timely execution is revealed. Moreover, the proposed method is shown to result in faster convergence in comparison with baseline schemes. Finally, useful insights for the selection of the quantization error tolerance are provided.