 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Line Search when you can Plane Search? SO-Friendly Neural Networks allow Per-Iteration Optimization of Learning and Momentum Rates for Every Layer
Paper and Code
Jun 25, 2024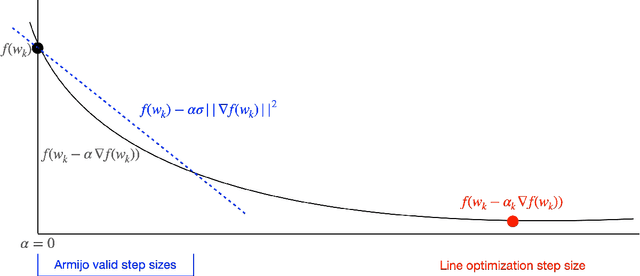
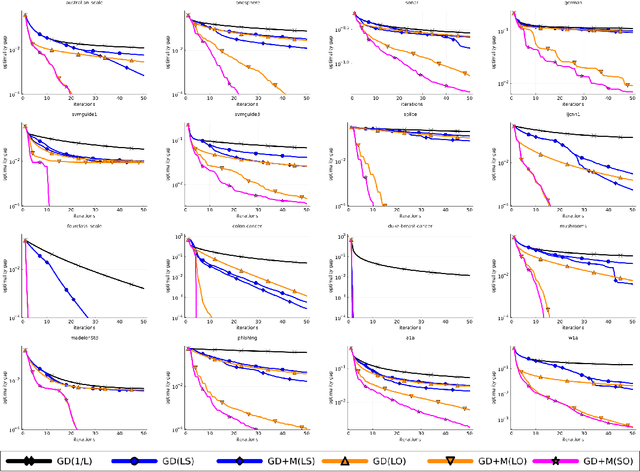
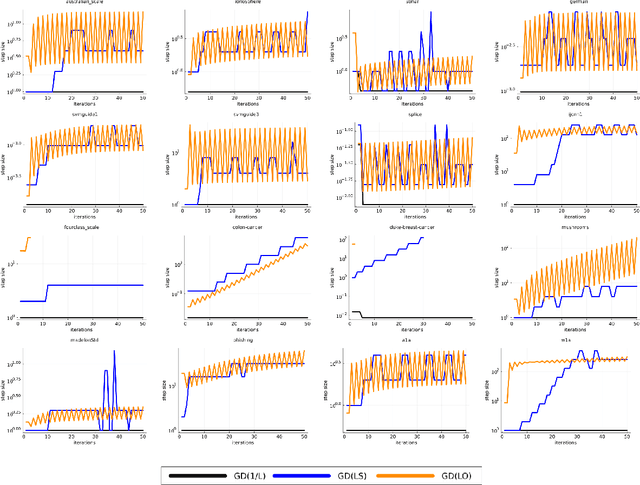
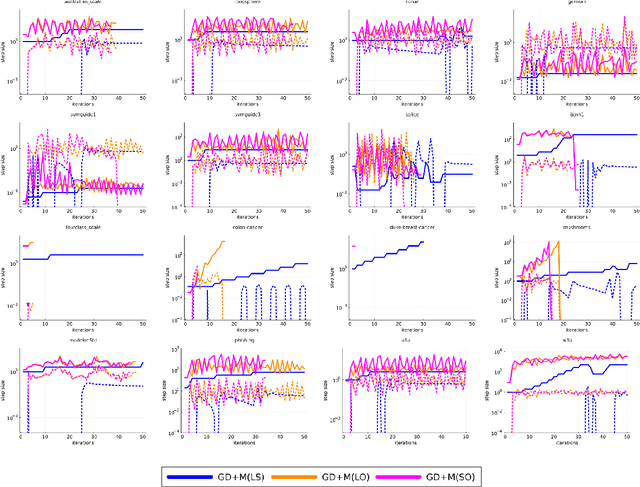
We introduce the class of SO-friendly neural networks, which include several models used in practice including networks with 2 layers of hidden weights where the number of inputs is larger than the number of outputs. SO-friendly networks have the property that performing a precise line search to set the step size on each iteration has the same asymptotic cost during full-batch training as using a fixed learning. Further, for the same cost a planesearch can be used to set both the learning and momentum rate on each step. Even further, SO-friendly networks also allow us to use subspace optimization to set a learning rate and momentum rate for each layer on each iteration. We explore augmenting gradient descent as well as quasi-Newton methods and Adam with line optimization and subspace optimization, and our experiments indicate that this gives fast and reliable ways to train these networks that are insensitive to hyper-parameters.