 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Lift so Heavy? Slimming Large Language Models by Cutting Off the Layers
Paper and Code
Feb 18, 2024
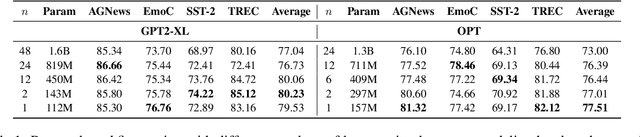
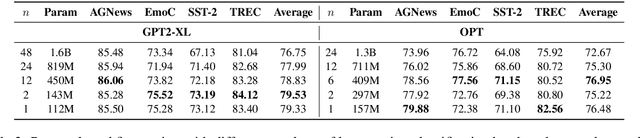
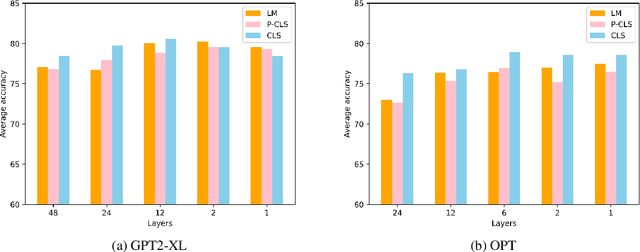
Large Language Models (LLMs) possess outstanding capabilities in addressing various natural language processing (NLP) tasks. However, the sheer size of these models poses challenges in terms of storage, training and inference due to the inclusion of billions of parameters through layer stacking. While traditional approaches such as model pruning or distillation offer ways for reducing model size, they often come at the expense of performance retention. In our investigation, we systematically explore the approach of reducing the number of layers in LLMs. Surprisingly, we observe that even with fewer layers, LLMs maintain similar or better performance levels, particularly in prompt-based fine-tuning for text classification tasks. Remarkably, in certain cases, models with a single layer outperform their fully layered counterparts. These findings offer valuable insights for future work aimed at mitigating the size constraints of LLMs while preserving their performance, thereby opening avenues for significantly more efficient use of LLMs.