Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy do classifier accuracies show linear trends under distribution shift?
Paper and Code
Dec 31, 2020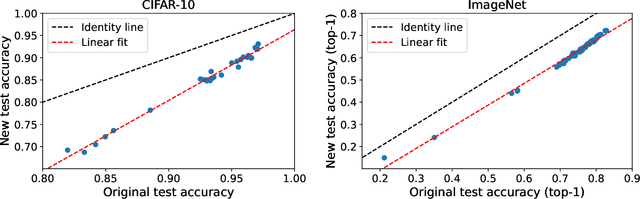
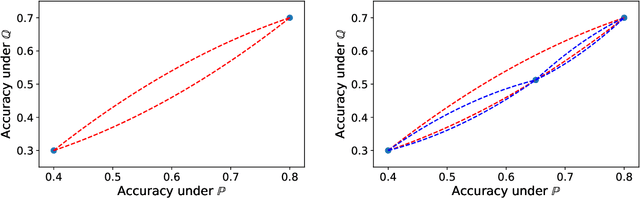
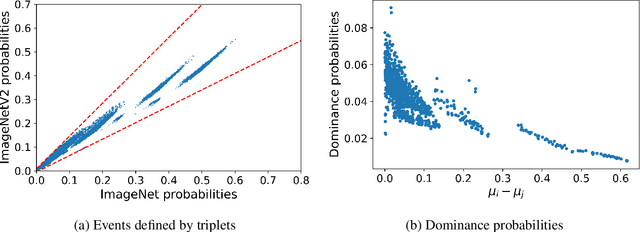
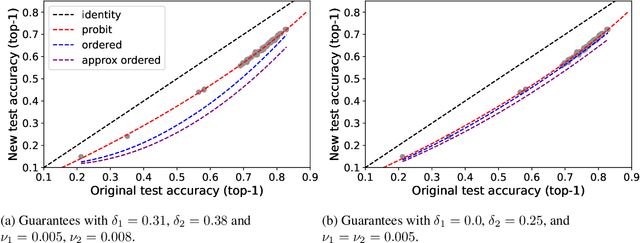
Several recent studies observed that when classification models are evaluated on two different data distributions, the models' accuracies on one distribution are approximately a linear function of their accuracies on another distribution. We offer an explanation for these observations based on two assumptions that can be assessed empirically: (1) certain events have similar probabilities under the two distributions; (2) the probability that a lower accuracy model correctly classifies a data point sampled from one distribution when a higher accuracy model classifies it incorrectly is small.
* 14 pages, 11 figures
View paper on