 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Deep Transformers are Difficult to Converge? From Computation Order to Lipschitz Restricted Parameter Initialization
Paper and Code
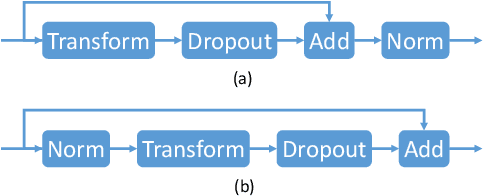
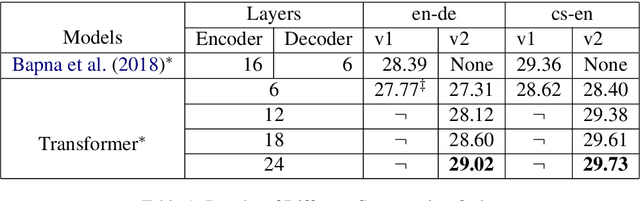

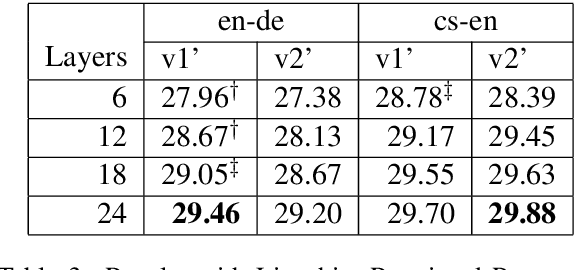
The Transformer translation model employs residual connection and layer normalization to ease the optimization difficulties caused by its multi-layer encoder/decoder structure. While several previous works show that even with residual connection and layer normalization, deep Transformers still have difficulty in training, and particularly a Transformer model with more than 12 encoder/decoder layers fails to converge. In this paper, we first empirically demonstrate that a simple modification made in the official implementation which changes the computation order of residual connection and layer normalization can effectively ease the optimization of deep Transformers. In addition, we deeply compare the subtle difference in computation order, and propose a parameter initialization method which simply puts Lipschitz restriction on the initialization of Transformers but can effectively ensure their convergence. We empirically show that with proper parameter initialization, deep Transformers with the original computation order can converge, which is quite in contrast to all previous works, and obtain significant improvements with up to 24 layers. Our proposed approach additionally enables to benefit from deep decoders compared to previous works which focus on deep encoders.