Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhittle index based Q-learning for restless bandits with average reward
Paper and Code
Apr 29, 2020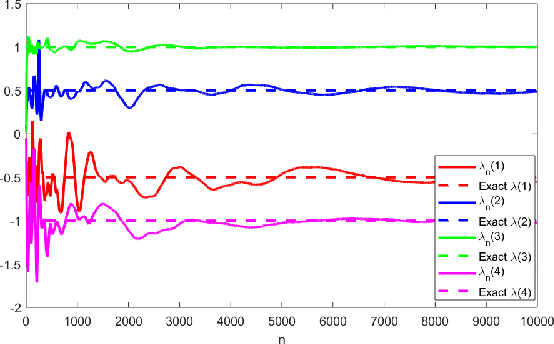
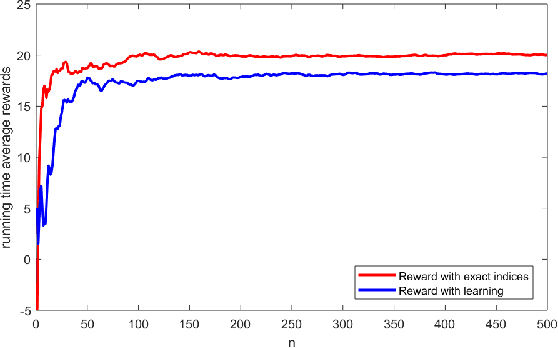
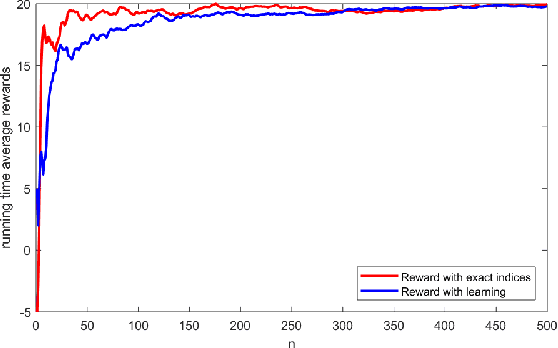
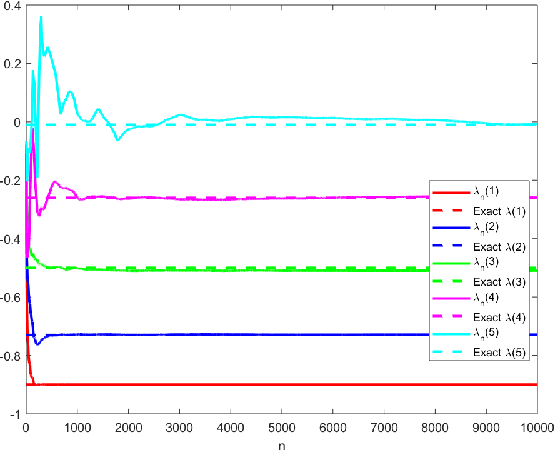
A novel reinforcement learning algorithm is introduced for multiarmed restless bandits with average reward, using the paradigms of Q-learning and Whittle index. Specifically, we leverage the structure of the Whittle index policy to reduce the search space of Q-learning, resulting in major computational gains. Rigorous convergence analysis is provided, supported by numerical experiments. The numerical experiments show excellent empirical performance of the proposed scheme.
View paper on