 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich transformer architecture fits my data? A vocabulary bottleneck in self-attention
Paper and Code



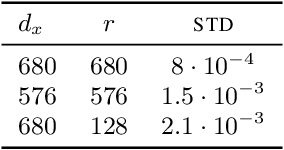
After their successful debut in natural language processing, Transformer architectures are now becoming the de-facto standard in many domains. An obstacle for their deployment over new modalities is the architectural configuration: the optimal depth-to-width ratio has been shown to dramatically vary across data types (e.g., $10$x larger over images than over language). We theoretically predict the existence of an embedding rank bottleneck that limits the contribution of self-attention width to the Transformer expressivity. We thus directly tie the input vocabulary size and rank to the optimal depth-to-width ratio, since a small vocabulary size or rank dictates an added advantage of depth over width. We empirically demonstrate the existence of this bottleneck and its implications on the depth-to-width interplay of Transformer architectures, linking the architecture variability across domains to the often glossed-over usage of different vocabulary sizes or embedding ranks in different domains. As an additional benefit, our rank bottlenecking framework allows us to identify size redundancies of $25\%-50\%$ in leading NLP models such as ALBERT and T5.