 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Backbone to Use: A Resource-efficient Domain Specific Comparison for Computer Vision
Paper and Code

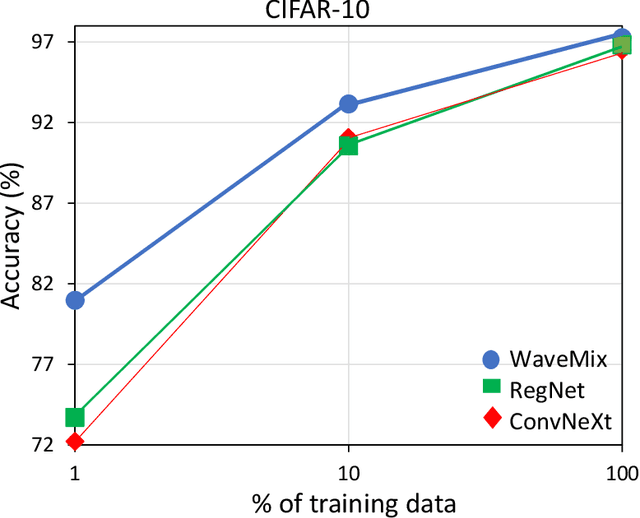

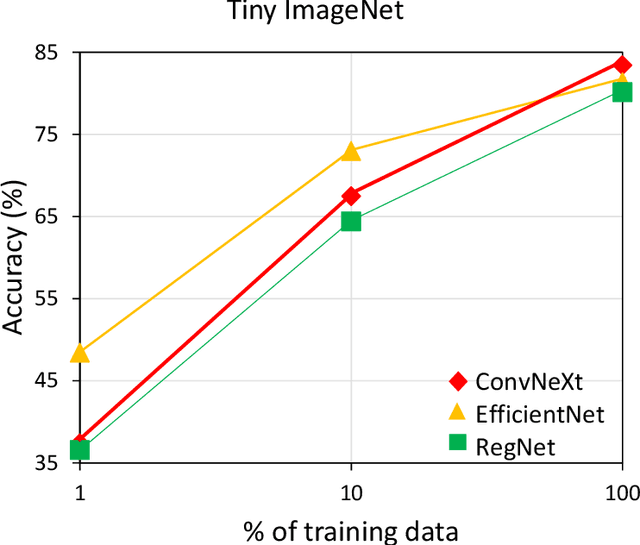
In contemporary computer vision applications, particularly image classification, architectural backbones pre-trained on large datasets like ImageNet are commonly employed as feature extractors. Despite the widespread use of these pre-trained convolutional neural networks (CNNs), there remains a gap in understanding the performance of various resource-efficient backbones across diverse domains and dataset sizes. Our study systematically evaluates multiple lightweight, pre-trained CNN backbones under consistent training settings across a variety of datasets, including natural images, medical images, galaxy images, and remote sensing images. This comprehensive analysis aims to aid machine learning practitioners in selecting the most suitable backbone for their specific problem, especially in scenarios involving small datasets where fine-tuning a pre-trained network is crucial. Even though attention-based architectures are gaining popularity, we observed that they tend to perform poorly under low data finetuning tasks compared to CNNs. We also observed that some CNN architectures such as ConvNeXt, RegNet and EfficientNet performs well compared to others on a diverse set of domains consistently. Our findings provide actionable insights into the performance trade-offs and effectiveness of different backbones, facilitating informed decision-making in model selection for a broad spectrum of computer vision domains. Our code is available here: https://github.com/pranavphoenix/Backbones