Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen and why randomised exploration works (in linear bandits)
Paper and Code
Feb 13, 2025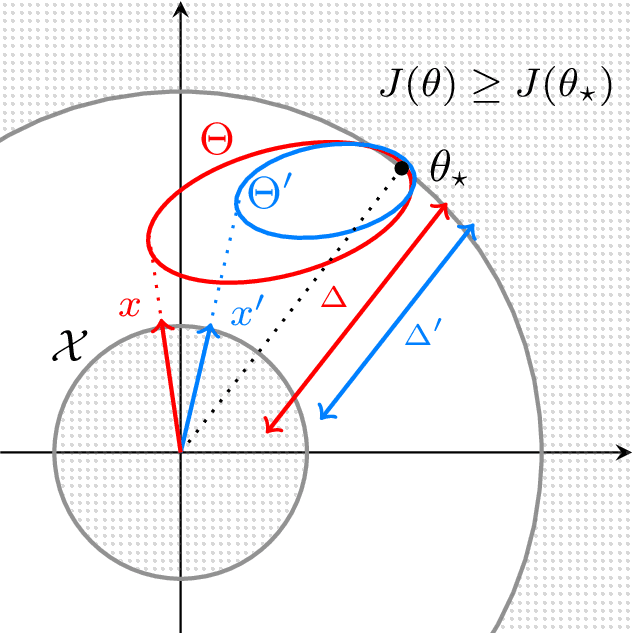
We provide an approach for the analysis of randomised exploration algorithms like Thompson sampling that does not rely on forced optimism or posterior inflation. With this, we demonstrate that in the $d$-dimensional linear bandit setting, when the action space is smooth and strongly convex, randomised exploration algorithms enjoy an $n$-step regret bound of the order $O(d\sqrt{n} \log(n))$. Notably, this shows for the first time that there exist non-trivial linear bandit settings where Thompson sampling can achieve optimal dimension dependence in the regret.
View paper on