Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Vision-Language Models `See' when they See Scenes
Paper and Code

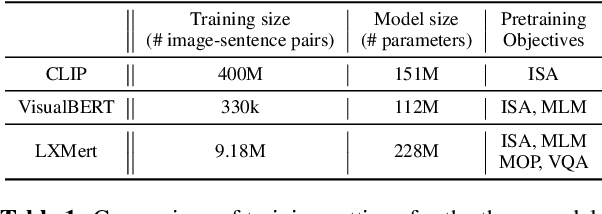
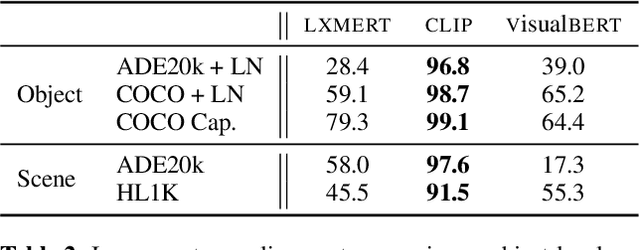
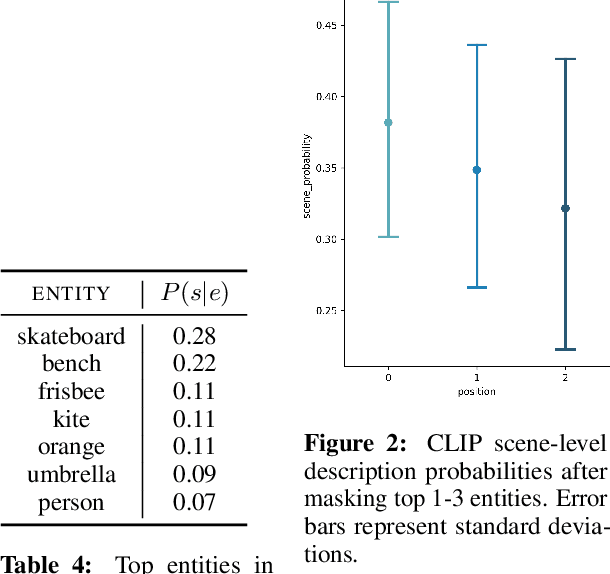
Images can be described in terms of the objects they contain, or in terms of the types of scene or place that they instantiate. In this paper we address to what extent pretrained Vision and Language models can learn to align descriptions of both types with images. We compare 3 state-of-the-art models, VisualBERT, LXMERT and CLIP. We find that (i) V&L models are susceptible to stylistic biases acquired during pretraining; (ii) only CLIP performs consistently well on both object- and scene-level descriptions. A follow-up ablation study shows that CLIP uses object-level information in the visual modality to align with scene-level textual descriptions.
View paper on