 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat can Large Language Models Capture about Code Functional Equivalence?
Paper and Code
Aug 20, 2024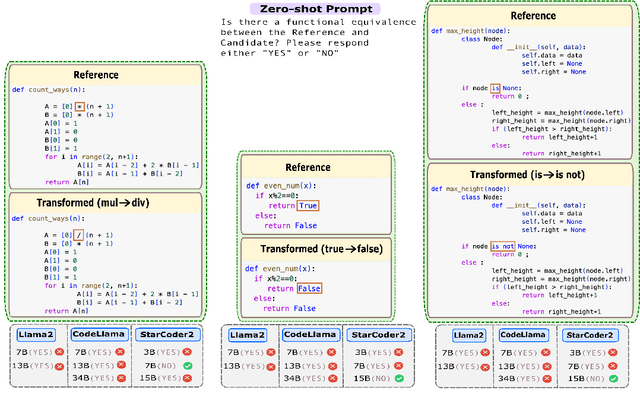
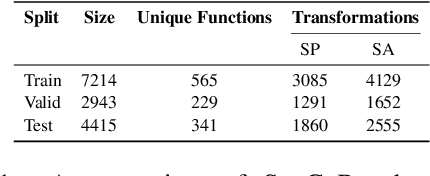
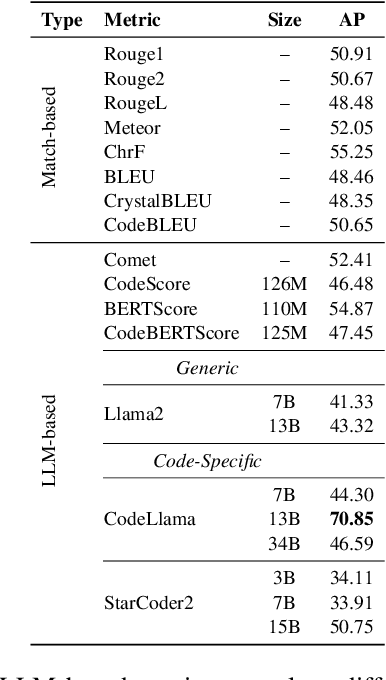
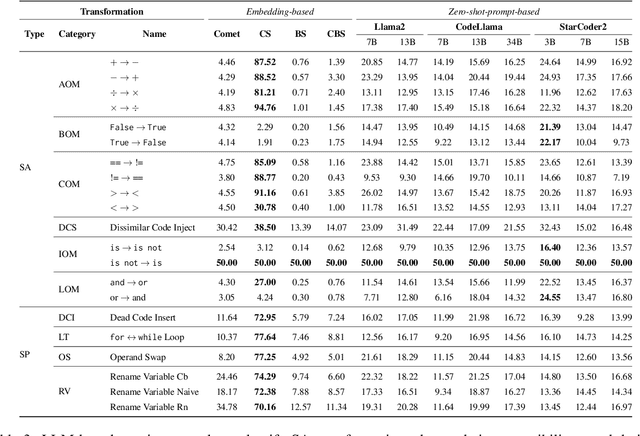
Code-LLMs, LLMs pre-trained on large code corpora, have shown great progress in learning rich representations of the structure and syntax of code, successfully using it to generate or classify code fragments. At the same time, understanding if they are able to do so because they capture code semantics, and how well, is still an open question. In this paper, we tackle this problem by introducing SeqCoBench, a benchmark for systematically assessing how Code-LLMs can capture code functional equivalence. SeqCoBench contains over 20 code transformations that either preserve or alter the semantics of Python programs. We conduct extensive evaluations in different settings, including zero-shot and parameter-efficient finetuning methods on state-of-the-art (Code-)LLMs to see if they can discern semantically equivalent or different pairs of programs in SeqCoBench. We find that the performance gap between these LLMs and classical match-based retrieval scores is minimal, with both approaches showing a concerning lack of depth in understanding code semantics.