 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Normalization based Quantization for Deep Neural Network Compression
Paper and Code
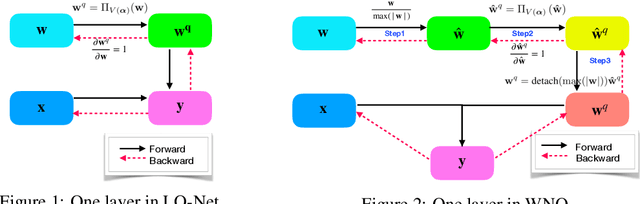
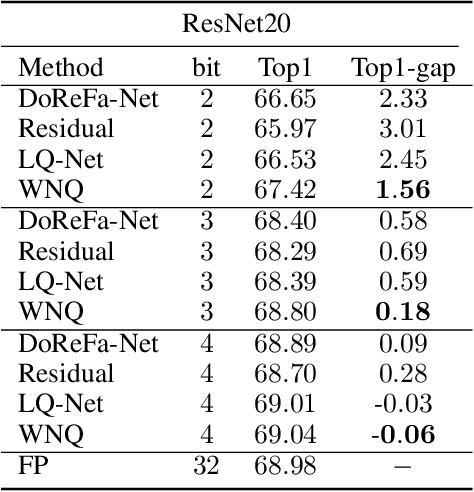
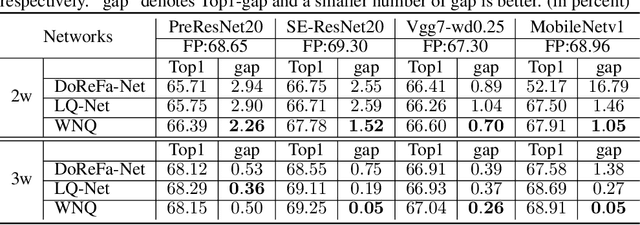
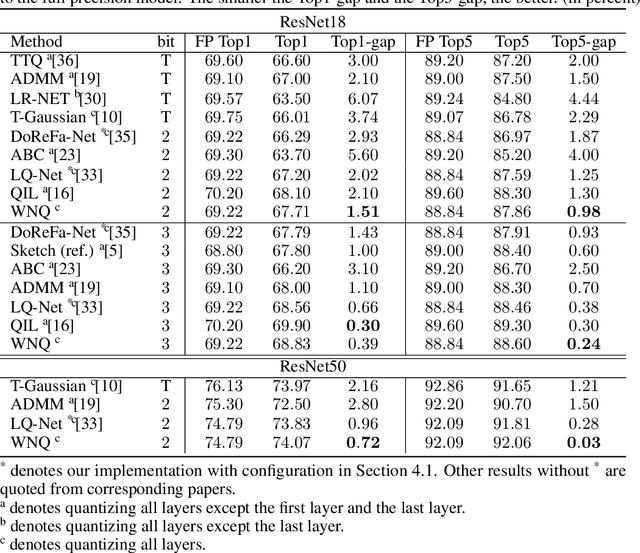
With the development of deep neural networks, the size of network models becomes larger and larger. Model compression has become an urgent need for deploying these network models to mobile or embedded devices. Model quantization is a representative model compression technique. Although a lot of quantization methods have been proposed, many of them suffer from a high quantization error caused by a long-tail distribution of network weights. In this paper, we propose a novel quantization method, called weight normalization based quantization (WNQ), for model compression. WNQ adopts weight normalization to avoid the long-tail distribution of network weights and subsequently reduces the quantization error. Experiments on CIFAR-100 and ImageNet show that WNQ can outperform other baselines to achieve state-of-the-art performance.