 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Training of Hierarchical Attention Networks for Speaker Identification
Paper and Code
May 15, 2020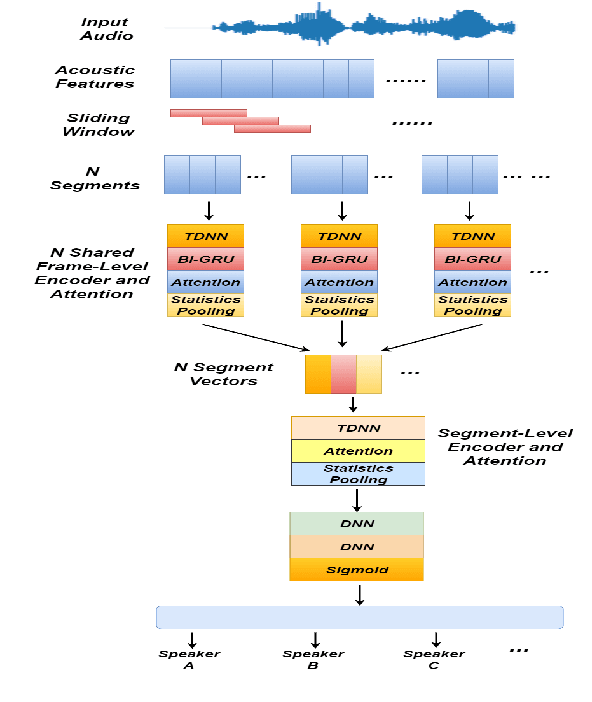

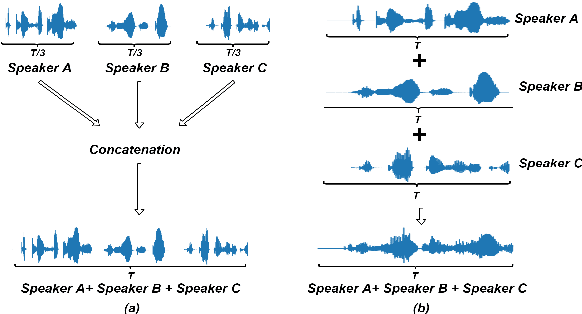
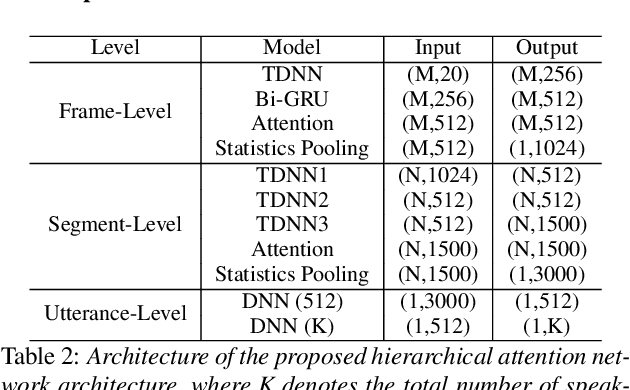
Identifying multiple speakers without knowing where a speaker's voice is in a recording is a challenging task. In this paper, a hierarchical attention network is proposed to solve a weakly labelled speaker identification problem. The use of a hierarchical structure, consisting of a frame-level encoder and a segment-level encoder, aims to learn speaker related information locally and globally. Speech streams are segmented into fragments. The frame-level encoder with attention learns features and highlights the target related frames locally, and output a fragment based embedding. The segment-level encoder works with a second attention layer to emphasize the fragments probably related to target speakers. The global information is finally collected from segment-level module to predict speakers via a classifier. To evaluate the effectiveness of the proposed approach, artificial datasets based on Switchboard Cellular part1 (SWBC) and Voxceleb1 are constructed in two conditions, where speakers' voices are overlapped and not overlapped. Comparing to two baselines the obtained results show that the proposed approach can achieve better performances. Moreover, further experiments are conducted to evaluate the impact of utterance segmentation. The results show that a reasonable segmentation can slightly improve identification performances.