 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Label Smoothing
Paper and Code
Dec 15, 2020

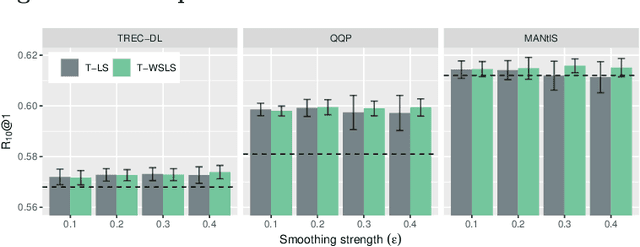
We study Label Smoothing (LS), a widely used regularization technique, in the context of neural learning to rank (L2R) models. LS combines the ground-truth labels with a uniform distribution, encouraging the model to be less confident in its predictions. We analyze the relationship between the non-relevant documents-specifically how they are sampled-and the effectiveness of LS, discussing how LS can be capturing "hidden similarity knowledge" between the relevantand non-relevant document classes. We further analyze LS by testing if a curriculum-learning approach, i.e., starting with LS and after anumber of iterations using only ground-truth labels, is beneficial. Inspired by our investigation of LS in the context of neural L2R models, we propose a novel technique called Weakly Supervised Label Smoothing (WSLS) that takes advantage of the retrieval scores of the negative sampled documents as a weak supervision signal in the process of modifying the ground-truth labels. WSLS is simple to implement, requiring no modification to the neural ranker architecture. Our experiments across three retrieval tasks-passage retrieval, similar question retrieval and conversation response ranking-show that WSLS for pointwise BERT-based rankers leads to consistent effectiveness gains. The source code is available at https://anonymous.4open.science/r/dac85d48-6f71-4261-a7d8-040da6021c52/.