 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised 3D Human Pose and Shape Reconstruction with Normalizing Flows
Paper and Code
Mar 23, 2020
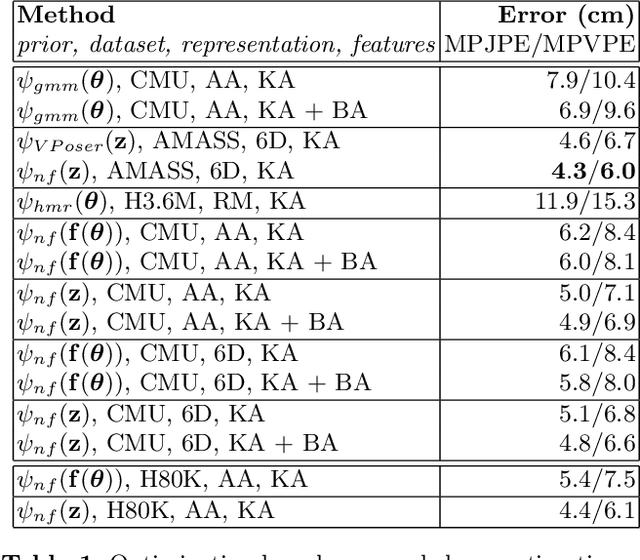


Monocular 3D human pose and shape estimation is challenging due to the many degrees of freedom of the human body and thedifficulty to acquire training data for large-scale supervised learning in complex visual scenes. In this paper we present practical semi-supervised and self-supervised models that support training and good generalization in real-world images and video. Our formulation is based on kinematic latent normalizing flow representations and dynamics, as well as differentiable, semantic body part alignment loss functions that support self-supervised learning. In extensive experiments using 3D motion capture datasets like CMU, Human3.6M, 3DPW, or AMASS, as well as image repositories like COCO, we show that the proposed methods outperform the state of the art, supporting the practical construction of an accurate family of models based on large-scale training with diverse and incompletely labeled image and video data.