Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgewav2vec: Unsupervised Pre-training for Speech Recognition
Paper and Code


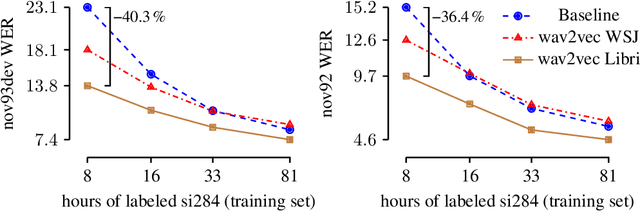

We explore unsupervised pre-training for speech recognition by learning representations of raw audio. wav2vec is trained on large amounts of unlabeled audio data and the resulting representations are then used to improve acoustic model training. We pre-train a simple multi-layer convolutional neural network optimized via a noise contrastive binary classification task. Our experiments on WSJ reduce WER of a strong character-based log-mel filterbank baseline by up to 32% when only a few hours of transcribed data is available. Our approach achieves 2.43% WER on the nov92 test set. This outperforms Deep Speech 2, the best reported character-based system in the literature while using three orders of magnitude less labeled training data.
View paper on