Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWav2Letter: an End-to-End ConvNet-based Speech Recognition System
Paper and Code
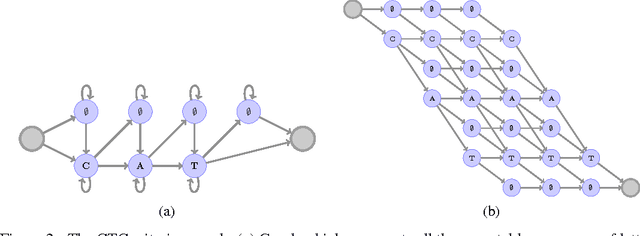



This paper presents a simple end-to-end model for speech recognition, combining a convolutional network based acoustic model and a graph decoding. It is trained to output letters, with transcribed speech, without the need for force alignment of phonemes. We introduce an automatic segmentation criterion for training from sequence annotation without alignment that is on par with CTC while being simpler. We show competitive results in word error rate on the Librispeech corpus with MFCC features, and promising results from raw waveform.
* 8 pages, 4 figures (7 plots/schemas), 2 tables (4 tabulars)
View paper on
 OpenReview
OpenReview