Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVSE++: Improving Visual-Semantic Embeddings with Hard Negatives
Paper and Code
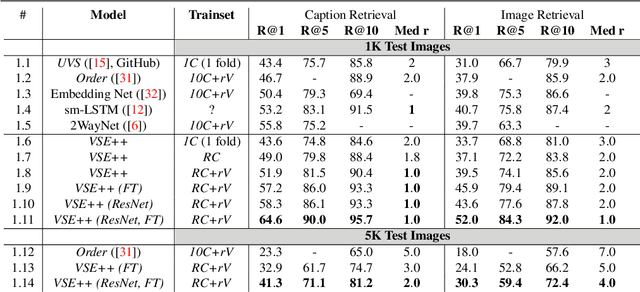
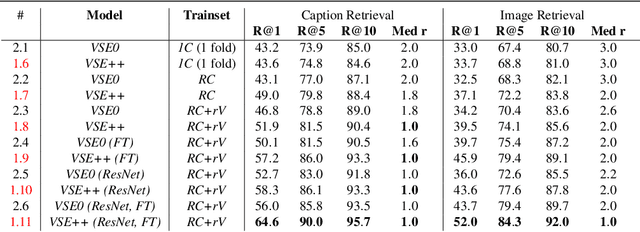
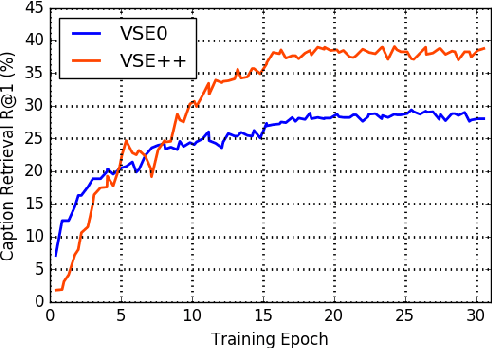
We present a new technique for learning visual-semantic embeddings for cross-modal retrieval. Inspired by hard negative mining, the use of hard negatives in structured prediction, and ranking loss functions, we introduce a simple change to common loss functions used for multi-modal embeddings. That, combined with fine-tuning and use of augmented data, yields significant gains in retrieval performance. We showcase our approach, VSE++, on MS-COCO and Flickr30K datasets, using ablation studies and comparisons with existing methods. On MS-COCO our approach outperforms state-of-the-art methods by 8.8% in caption retrieval and 11.3% in image retrieval (at R@1).
* Accepted as spotlight presentation at British Machine Vision
Conference (BMVC) 2018. Code: https://github.com/fartashf/vsepp
View paper on
 OpenReview
OpenReview