Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQD: Visual Query Detection in Natural Scenes
Paper and Code
Apr 11, 2019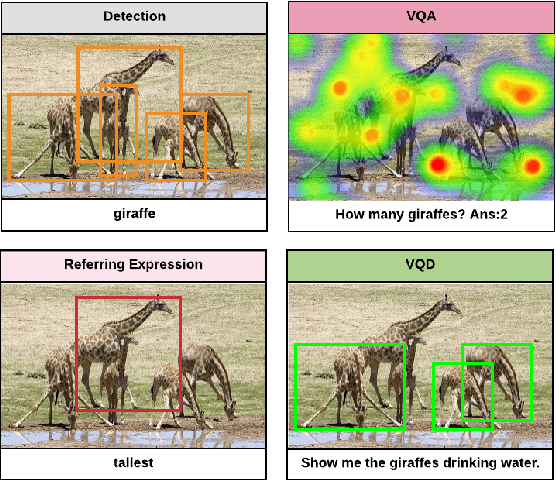


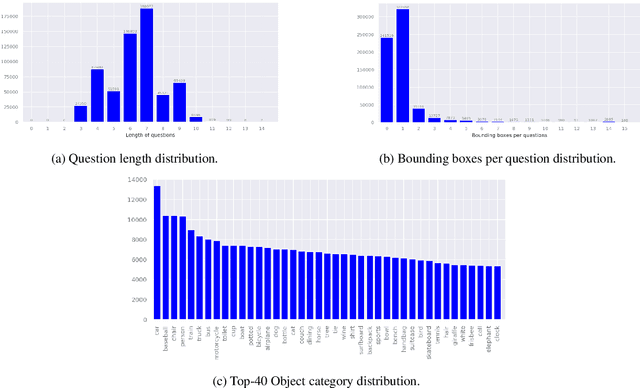
We propose Visual Query Detection (VQD), a new visual grounding task. In VQD, a system is guided by natural language to localize a variable number of objects in an image. VQD is related to visual referring expression recognition, where the task is to localize only one object. We describe the first dataset for VQD and we propose baseline algorithms that demonstrate the difficulty of the task compared to referring expression recognition.
* To appear in NAACL 2019 ( To download the dataset please go to
http://www.manojacharya.com/ )
View paper on